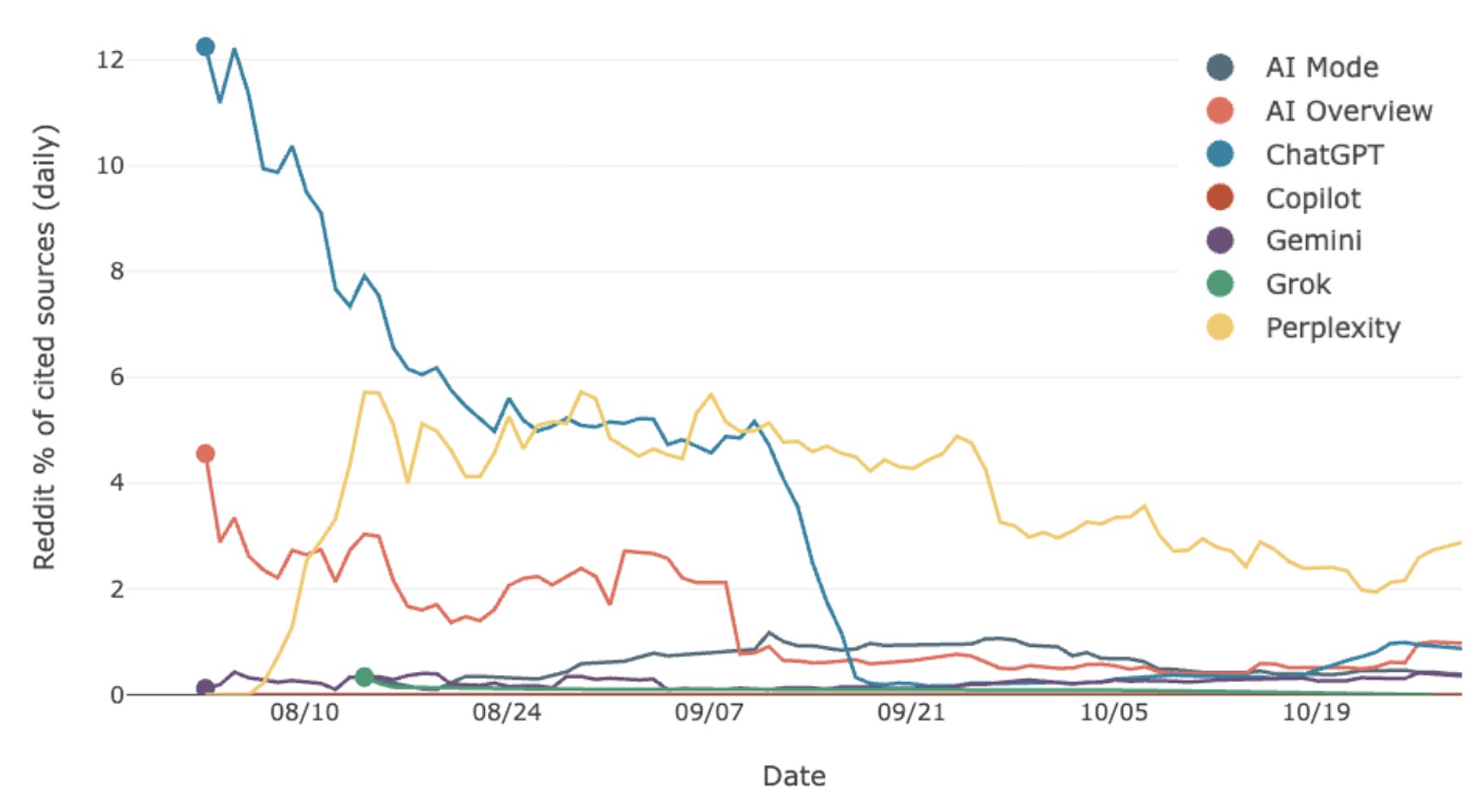
When someone asks ChatGPT about your industry or products, you want your brand to be mentioned. Getting ChatGPT to mention your brand requires special strategies called GEO (Generative Engine Optimization) and AEO (Answer Engine Optimization). These are part of a broader approach known as AI SEO or AI visibility optimization.
GEO and AEO tools help you track when ChatGPT and other AI assistants mention your brand, show you where you’re missing opportunities, and guide you on how to optimize your content so AI systems will reference it. Whether you’re focused on ChatGPT specifically or want visibility across multiple AI platforms, these tools provide the insights you need to improve your AI visibility.
This guide covers the top 10 GEO and SEO tools designed to get ChatGPT mentioning your brand in December 2025. Each tool offers unique features for AI visibility tracking, content optimization, and brand mention improvement across ChatGPT and other major AI platforms.
What Are GEO, AEO, and AI SEO?
GEO stands for Generative Engine Optimization. It’s the practice of optimizing your content so that AI systems like ChatGPT are more likely to cite and reference it in their responses. According to research from Wikipedia, GEO focuses on making your content citation-worthy for generative answer engines.
AEO stands for Answer Engine Optimization. This is an older term that covers optimizing for answer-first experiences beyond traditional search, including featured snippets, knowledge panels, and voice assistants. AEO helps you become the direct answer that AI systems provide.
AI SEO combines traditional SEO thinking with AI-powered search surfaces. It applies SEO strategies to AI assistants, chat interfaces, and AI-generated summaries. The goal is to improve your AI visibility across all these surfaces.
AI visibility is the overall measure of how often and how accurately your brand appears in AI-generated responses. Improving your AI visibility means more people will discover your brand when they ask AI assistants questions related to your products or services.
Top 10 GEO / SEO Tools to Get ChatGPT Mentioning Your Brand
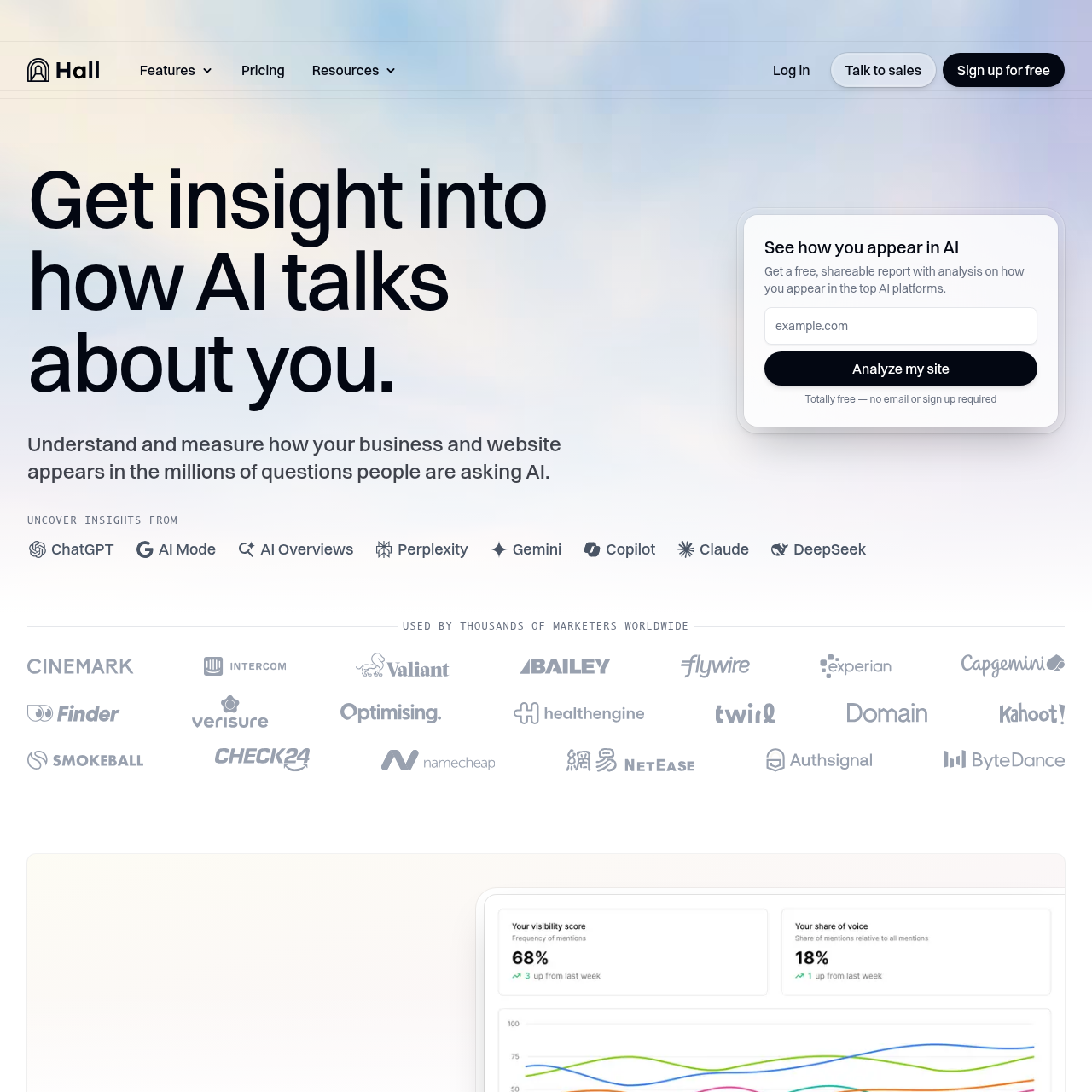
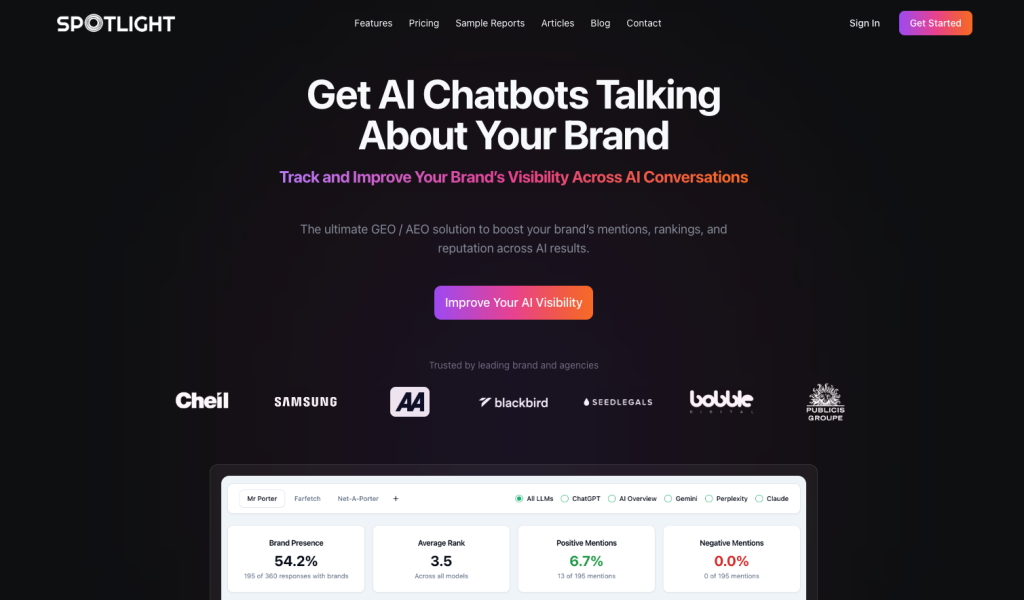
Spotlight
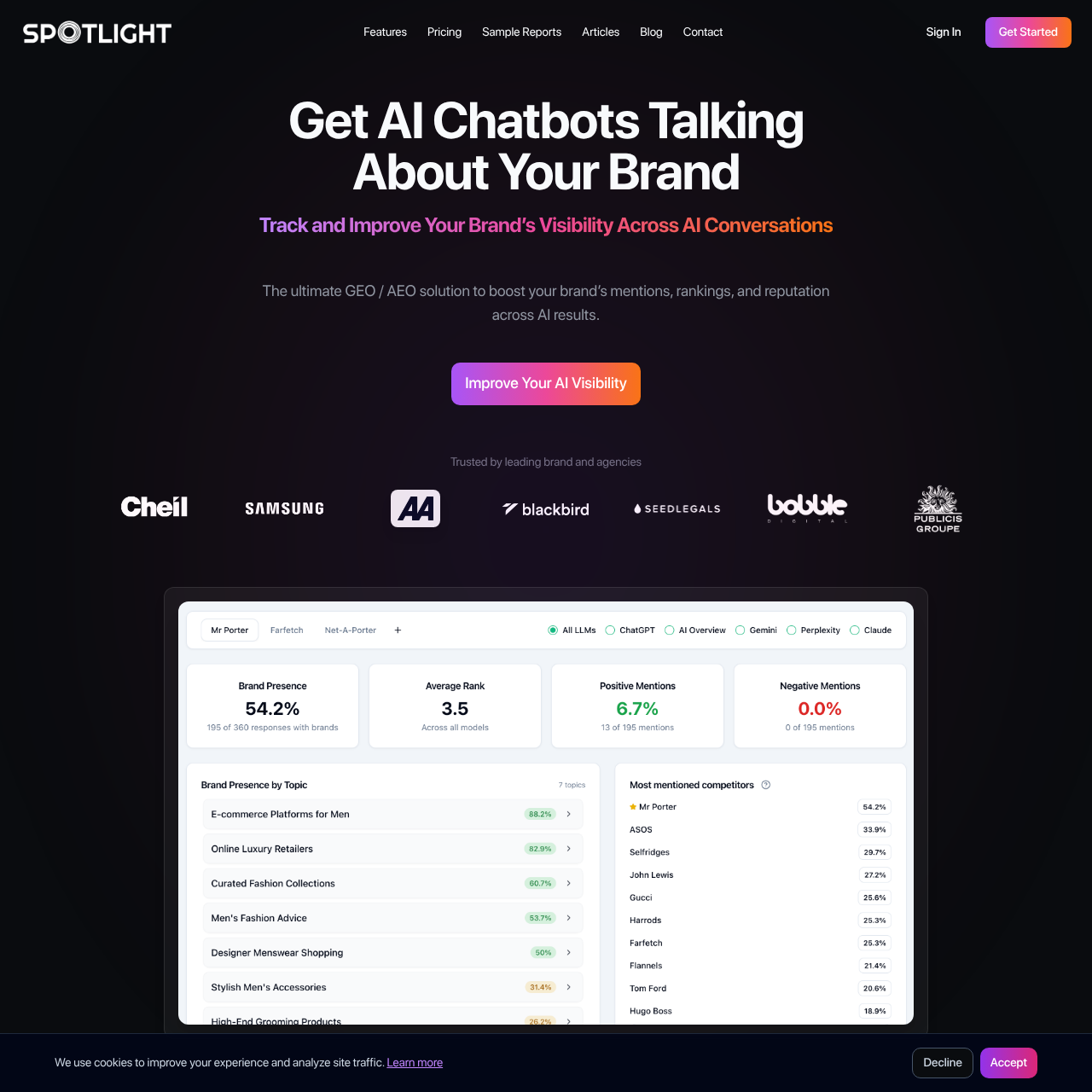
Spotlight is a leading GEO and AI SEO platform that tracks and optimizes brand presence across ChatGPT and other major AI chatbots. The platform combines comprehensive AI visibility monitoring with proactive GEO optimization, helping brands understand where they appear in ChatGPT responses and how to improve their visibility.
What makes Spotlight stand out is its support for all languages and coverage of 8+ major AI platforms including ChatGPT. The platform provides prompt volume analytics, showing you how often people ask questions related to your brand in ChatGPT and other AI assistants. This helps you understand the demand for information about your products or services.
Spotlight goes beyond monitoring to provide intelligent content suggestions that improve AI visibility and brand mentions. The platform analyzes the actual keywords that LLMs like ChatGPT use when fetching data for their responses, along with all the data sources that AI models cite. Based on this analysis, Spotlight suggests content that aligns with what’s already being cited, plus unique perspectives that offer added value—increasing your chances of being referenced by ChatGPT and other AI systems.
Spotlight’s free tier makes it accessible for early-stage brands, while paid plans unlock advanced GEO and AI SEO features for growing teams. The platform surfaces citation gaps and optimization opportunities, giving you actionable insights to improve your ChatGPT visibility.
Best For: Businesses of all sizes that need comprehensive GEO and AI SEO tracking across ChatGPT and multiple AI platforms.
GEOAEOAI SEOChatGPT
Scrunch AI
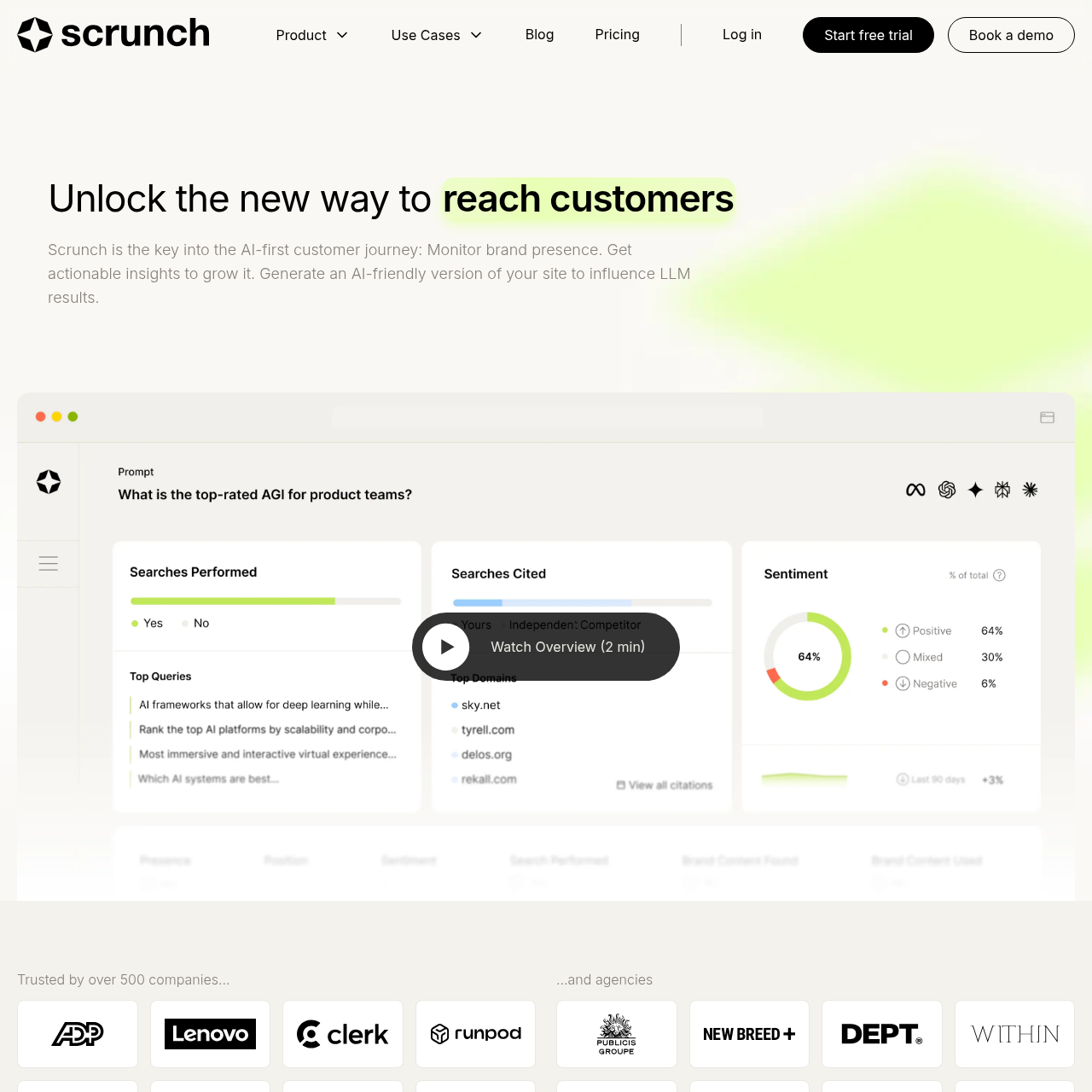
Scrunch AI provides enterprise-grade proactive monitoring and GEO optimization for AI search results, identifying content gaps, misinformation, and improvements across ChatGPT and Google AI Overviews. The platform leans into enterprise-grade content intelligence, flagging misinformation, content gaps, and optimization opportunities across AI search experiences.
With broad coverage across every major LLM including ChatGPT and a focus on content quality and accuracy, Scrunch AI is positioned for larger organizations that need comprehensive AI visibility and content strategy guidance. The platform helps brands understand where they appear in ChatGPT and identifies opportunities to improve their GEO performance.
The higher price point reflects its enterprise positioning and extensive coverage. Scrunch AI’s content gap analysis helps you identify where your brand should appear in ChatGPT but doesn’t, giving you actionable insights for GEO optimization.
Best For: Enterprise organizations that need comprehensive GEO and AI SEO tracking across ChatGPT and multiple AI platforms with content intelligence.
GEOEnterpriseContent Intelligence
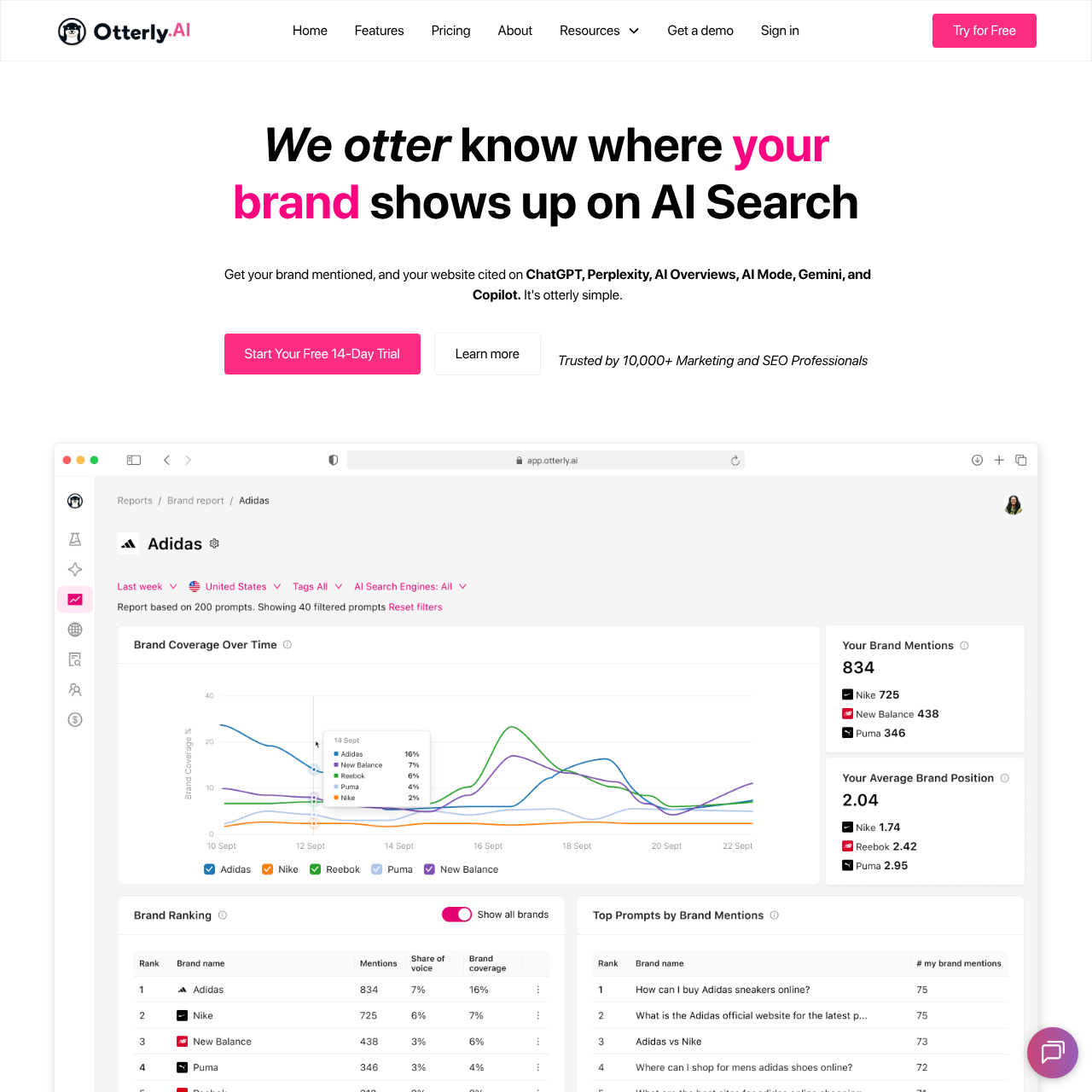
Peec AI
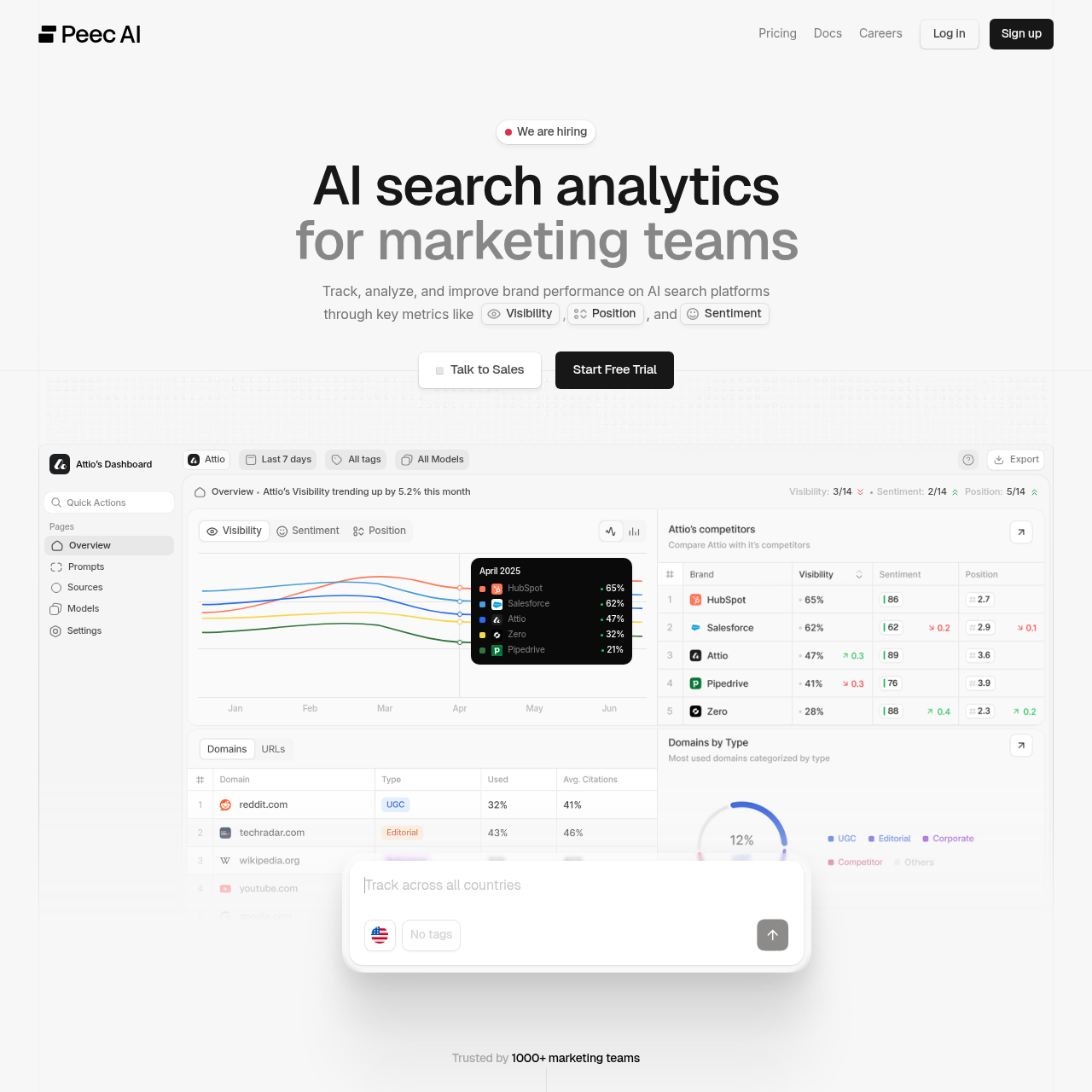
Peec AI tracks visibility, benchmarks competitors, analyzes sources, and provides trends in AI engines like ChatGPT, Perplexity, and Deepseek, with prompt suggestions and multi-language support. The platform emphasizes competitive benchmarking, trend analysis, and actionable prompt suggestions to steer content strategies for GEO optimization.
With coverage of ChatGPT, Perplexity, and Deepseek, plus prompt volume data, Peec AI offers a balanced approach to monitoring and optimization for brands looking to understand their competitive position in ChatGPT responses. The platform helps you see how your brand compares to competitors and identifies opportunities to improve your GEO performance.
Peec AI’s source analysis feature helps you understand which websites ChatGPT references when discussing topics related to your brand. This insight is valuable for GEO optimization, as it shows you what types of content ChatGPT prefers to cite.
Best For: International brands that want competitive benchmarking and trend analysis for ChatGPT visibility using GEO strategies.
GEOCompetitive AnalysisBenchmarking
Promptmonitor
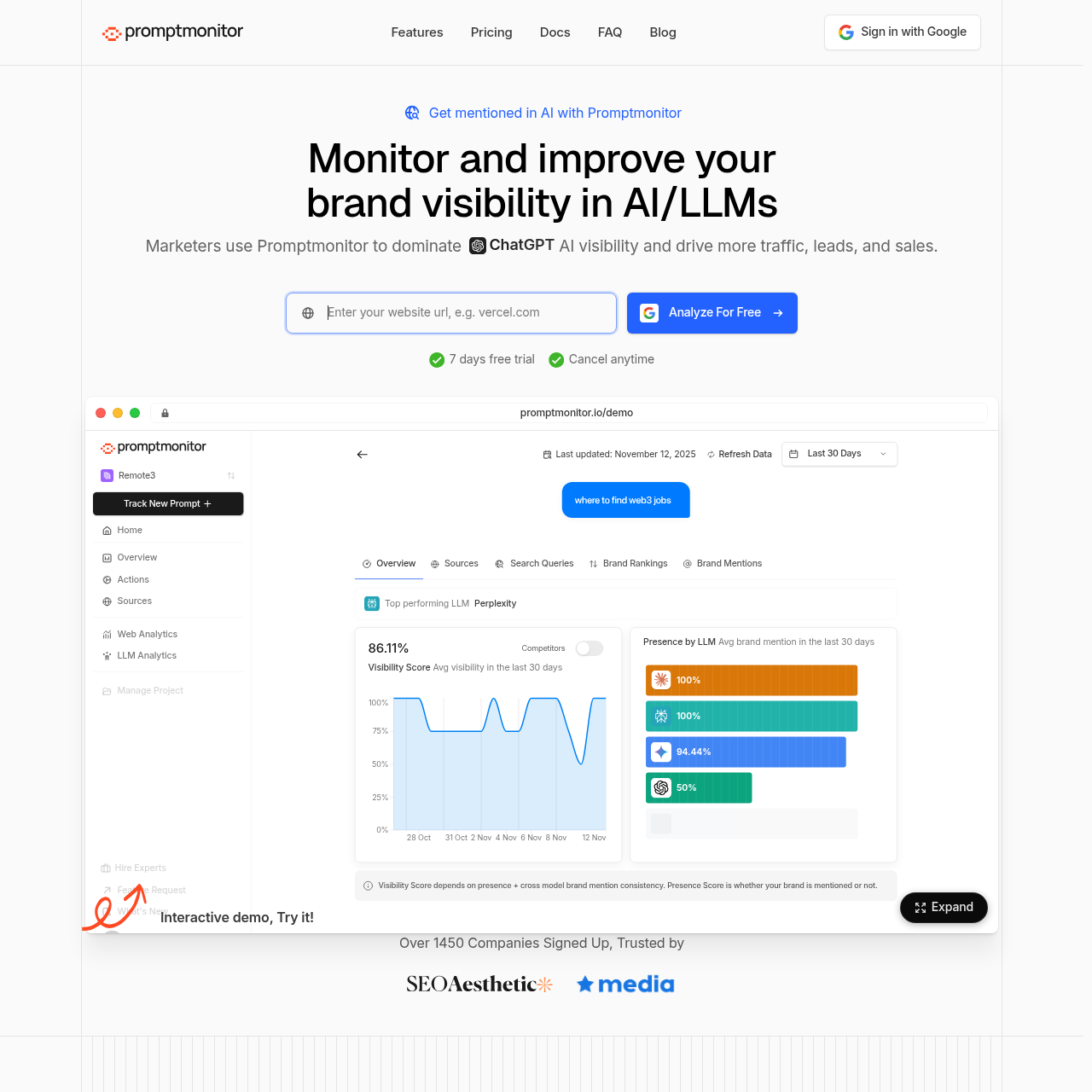
Promptmonitor offers multi-model prompt tracking across 8+ LLMs including ChatGPT, AI crawler analytics, competitor monitoring, and source discovery with SEO metrics. The platform blends AI crawler analytics with SEO-integrated metrics, delivering a hybrid view of search and generative visibility for GEO optimization.
With coverage of 8+ major AI platforms including ChatGPT, Claude, Gemini, DeepSeek, Grok, Perplexity, Google AI Overview, and AI Mode, Promptmonitor provides comprehensive multi-model tracking at an affordable price point. The SEO integration makes it particularly valuable for teams already focused on traditional search optimization who want to add AI SEO and GEO strategies.
The platform’s competitor monitoring feature helps you understand how your brand’s ChatGPT visibility compares to competitors, giving you actionable insights for improving your GEO performance. The AI crawler analytics provide deep insights into how ChatGPT and other AI systems discover and reference your content.
Best For: Teams that want comprehensive GEO and AI SEO tracking across ChatGPT and multiple AI platforms with SEO integration.
GEOAI SEOMulti-Model
Mentions.so
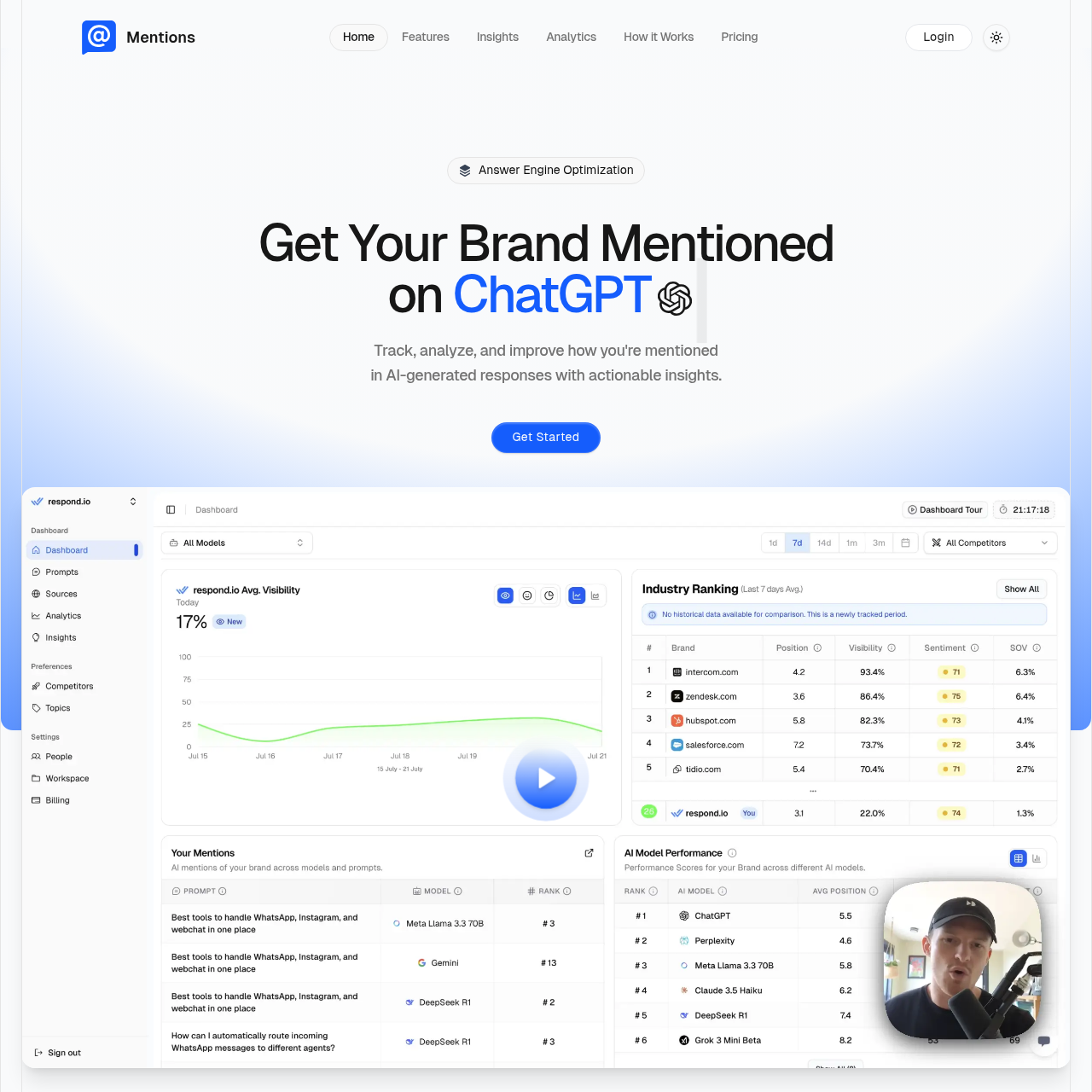
Mentions.so provides AI traffic analytics, performance updates, and white-label reports for tracking brand citations in ChatGPT and other generative AI platforms. The platform packages comprehensive AI traffic analytics with white-label reporting capabilities, making it specifically tailored for agencies seeking professional client-facing GEO dashboards.
The platform’s focus on reporting and analytics makes it ideal for agencies that need to present GEO insights to multiple clients in a branded format. Mentions.so helps agencies track their clients’ ChatGPT visibility and provides white-label reports that agencies can customize with their own branding.
Mentions.so’s AI traffic analytics help you understand how much traffic comes from ChatGPT and other AI platforms, giving you insights into the ROI of your GEO efforts. The performance updates keep you informed about changes in your ChatGPT visibility over time.
Best For: Agencies that need white-label GEO reporting and AI visibility analytics for multiple clients, including ChatGPT tracking.
GEOAgencyWhite-Label
Authoritas AI Search
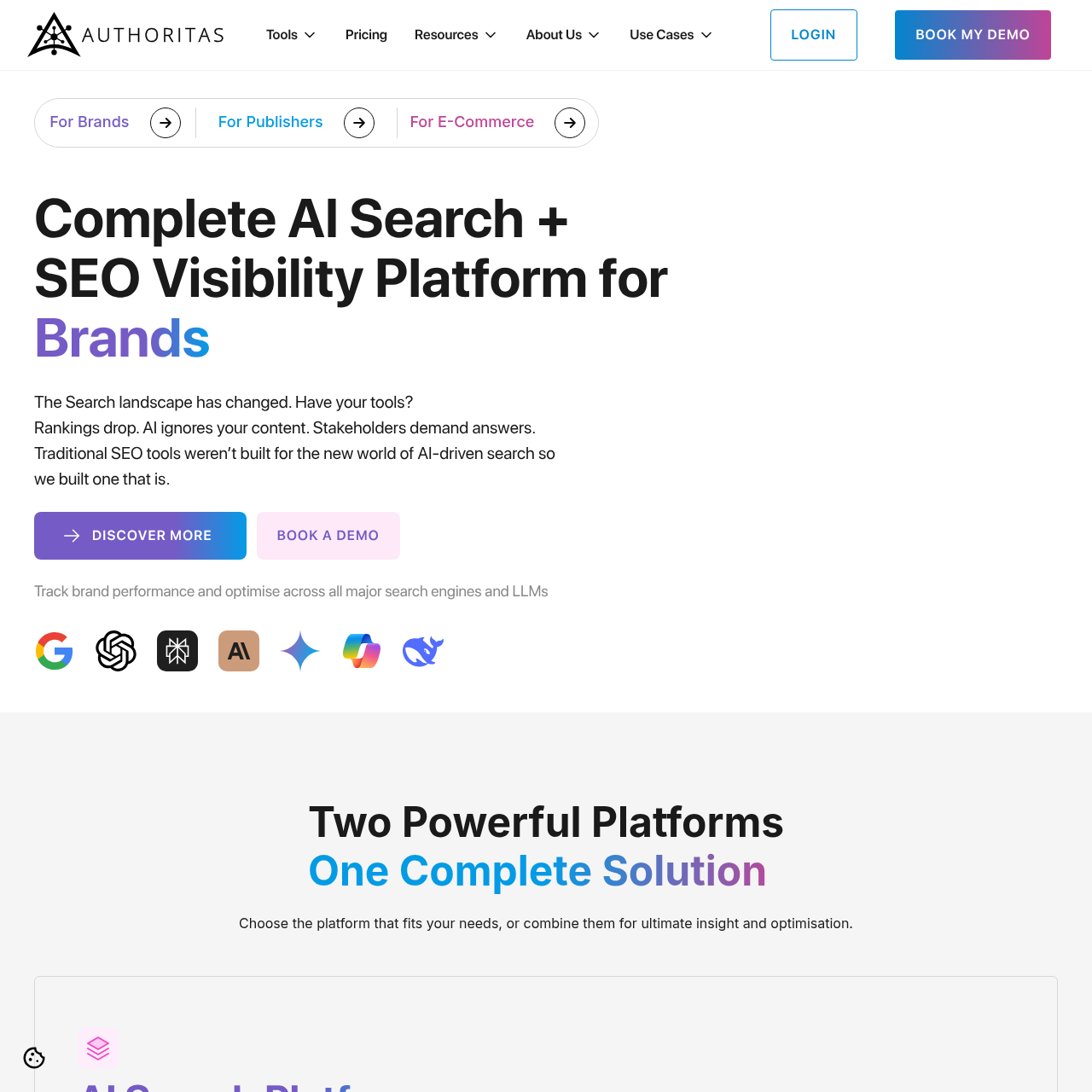
Authoritas AI Search offers comprehensive tracking of mentions, share of voice, citations, and custom prompts across ChatGPT and multiple LLMs. The platform unifies share-of-voice tracking with custom prompts and multilingual analytics for enterprise marketing teams, providing enterprise-grade GEO intelligence.
With coverage of 7 major platforms including ChatGPT, Gemini, Perplexity, Claude, DeepSeek, Google AI Overviews, and Bing AI, plus language customization capabilities, Authoritas delivers comprehensive AI visibility tracking. The share-of-voice metrics make it particularly valuable for competitive analysis and market positioning strategies in ChatGPT responses.
The platform’s custom prompts feature allows you to test specific questions that people might ask ChatGPT about your brand, helping you understand your current GEO performance and identify opportunities for improvement. The multilingual analytics make it valuable for international brands.
Best For: Enterprise marketing teams that need share-of-voice tracking and comprehensive GEO analytics across ChatGPT and multiple AI platforms.
GEOEnterpriseShare of Voice
XFunnel
XFunnel provides visibility monitoring with competitive positioning, sentiment, and query segmentation by market/persona for ChatGPT and other AI platforms. The platform delivers competitive positioning and market segmentation insights, blending sentiment analysis with GEO performance.
With coverage of 7 major platforms including ChatGPT, Gemini, Copilot, Claude, Perplexity, AI Overview, and AI Mode, plus prompt volume data, XFunnel offers enterprise-grade competitive intelligence. The query segmentation by market and persona makes it particularly valuable for brands targeting specific customer segments or geographic markets in ChatGPT responses.
XFunnel’s sentiment analysis helps you understand how ChatGPT presents your brand—positively, negatively, or neutrally. This insight is valuable for GEO optimization, as it helps you identify areas where your brand narrative might need improvement in ChatGPT responses.
Best For: Enterprise teams that need competitive positioning and market segmentation insights for ChatGPT visibility using GEO strategies.
GEOCompetitive IntelSentiment
Waikay
Waikay monitors brand representation with AI Brand Score, fact-checking, competitor comparison, and knowledge graph building for ChatGPT and other AI platforms. The platform introduces an AI Brand Score with fact-checking and knowledge graph insights, designed for multilingual reach.
With coverage of ChatGPT, Google, Claude, and Sonar, plus support for 13 languages, Waikay offers comprehensive international coverage at one of the most affordable price points in the market. The fact-checking feature is unique and valuable for brands concerned about accuracy in ChatGPT-generated content about their business.
Waikay’s AI Brand Score provides a single metric that summarizes your overall ChatGPT visibility, making it easy to track your GEO performance over time. The knowledge graph building feature helps you understand how ChatGPT associates your brand with different topics and entities.
Best For: Budget-conscious brands that need affordable GEO tracking and fact-checking for ChatGPT visibility across multiple languages.
GEOAI VisibilityBudget-Friendly
RankScale
RankScale is a GEO platform for audits, performance tracking, citations, and content recommendations in ChatGPT and other AI search engines. The platform delivers comprehensive GEO audits and performance tracking with competitive benchmarking for AI search engines.
Currently in beta, RankScale focuses on providing actionable insights through audits and content recommendations, making it valuable for teams that want structured guidance on improving their ChatGPT visibility. The audit feature provides a comprehensive assessment of your current GEO performance and identifies specific areas for improvement.
RankScale’s content recommendations help you understand what types of content you should create to improve your ChatGPT visibility. The competitive benchmarking feature shows you how your GEO performance compares to competitors, giving you targets to aim for.
Best For: Teams that want structured GEO audits and content recommendations to improve their ChatGPT visibility with a strategic approach.
GEOAuditsContent Recommendations
ModelMonitor
ModelMonitor tracks across 50+ AI models including ChatGPT, with prompt radar, custom monitoring, competitor analysis, and sentiment. The platform broadens visibility with prompt radar, sentiment insights, and custom monitoring for large model portfolios.
ModelMonitor’s claim of 50+ model coverage makes it one of the most comprehensive options for brands that need visibility across a wide range of AI platforms, including ChatGPT. The affordable pricing combined with extensive coverage makes it attractive for teams that prioritize breadth over depth in specific platforms.
The platform’s prompt radar feature helps you discover what questions people are asking across different AI models, including ChatGPT. This insight is valuable for GEO optimization, as it helps you create content that answers the questions your customers are actually asking.
Best For: Teams that need broad GEO coverage across ChatGPT and many other AI models with affordable pricing.
GEOWide Coverage50+ Models
How Do GEO and AI SEO Tools Help Get ChatGPT to Mention Your Brand?
GEO and AI SEO tools work in several ways to help your brand appear more often and more accurately in ChatGPT responses:
- Tracking Mentions: These tools monitor when your brand gets mentioned in ChatGPT responses. This helps you understand your current AI visibility and track changes over time.
- Identifying Gaps: The platforms show you where your brand should appear in ChatGPT but doesn’t. This helps you identify opportunities to create content that fills these gaps using GEO strategies.
- Content Optimization: Many tools provide recommendations for improving your existing content so ChatGPT is more likely to reference it. This might include adding specific keywords, improving structure, or adding authoritative citations—all key GEO tactics.
- Competitive Analysis: You can see how your brand compares to competitors in ChatGPT responses. This helps you understand your market position and identify areas for improvement in your AI visibility.
- Prompt Intelligence: Some platforms show you what questions people are asking ChatGPT that relate to your brand. This helps you create content that answers these questions, improving your GEO performance.
What Should You Look for in a GEO or AI SEO Tool?
When choosing a GEO or AI SEO tool to get ChatGPT mentioning your brand, consider these factors:
- ChatGPT Coverage: Make sure the tool tracks ChatGPT specifically, as this is often the primary AI platform where brands want visibility. Some tools focus exclusively on ChatGPT, while others cover multiple platforms.
- GEO Features: Look for tools that offer GEO optimization features, not just monitoring. You want a tool that helps you improve your AI visibility, not just track it.
- AI SEO Integration: If you already use SEO tools, look for platforms that integrate GEO and AI SEO with your existing workflow. This helps you manage both traditional SEO and AI visibility in one place.
- Prompt Volume Data: Understanding what questions people ask ChatGPT about your industry helps you create better content. Look for tools that provide prompt volume analytics.
- Ease of Use: Consider how easy the tool is to use. If you have a small team without technical expertise, look for beginner-friendly platforms with intuitive interfaces.
- Pricing: GEO and AI SEO tools range from free tiers to enterprise pricing. Consider your budget and choose a tool that provides value for your investment.
Why Is Getting ChatGPT to Mention Your Brand Important?
As more people use ChatGPT to find information, appearing in ChatGPT responses becomes crucial for brand awareness and customer acquisition. According to research, ChatGPT and other AI assistants are becoming a primary way people discover products and services.
When someone asks ChatGPT about your industry or products, you want your brand to be mentioned. If you’re not visible in ChatGPT responses, you’re missing out on potential customers who are actively looking for what you offer. This is where GEO and AI SEO strategies become essential.
GEO and AI SEO tools help you understand where you appear in ChatGPT, where you’re missing, and how to improve. This gives you a competitive advantage in the growing world of AI-powered search and discovery.
Frequently Asked Questions
What is the difference between GEO and AEO?
GEO (Generative Engine Optimization) focuses on optimizing content for generative answer engines like ChatGPT that synthesize web sources into a single response. AEO (Answer Engine Optimization) is an older term that covers optimizing for answer-first experiences including featured snippets, knowledge panels, and voice assistants. Both are part of AI SEO strategies for improving AI visibility.
How is AI SEO different from traditional SEO?
Traditional SEO focuses on ranking in search engine results pages. AI SEO applies SEO thinking to AI-powered surfaces like ChatGPT, AI overviews, and chat interfaces. AI SEO uses GEO and AEO strategies to improve your AI visibility across these new discovery channels.
How much do GEO and AI SEO tools cost?
GEO and AI SEO tools range from free tiers (like Spotlight) to enterprise pricing around $300 per month. Most tools fall in the $20 to $200 per month range, making them accessible for businesses of various sizes.
Do I need technical expertise to use GEO tools?
Most GEO and AI SEO tools are designed to be user-friendly, with many platforms requiring no technical expertise. However, some enterprise tools may have more advanced features that benefit from marketing or SEO knowledge.
How long does it take to see results from GEO optimization?
Results can vary depending on your industry and the changes you make. Some improvements in ChatGPT visibility may be visible within weeks, while others may take months. The key is to consistently create high-quality content that answers questions your customers are asking ChatGPT, using GEO principles.
Should I focus only on ChatGPT or multiple AI platforms?
While ChatGPT is currently the most popular AI assistant, other platforms like Google AI Overviews, Gemini, and Perplexity are also important. Many GEO tools track multiple platforms, so you can monitor your AI visibility across all of them. However, if most of your customers use ChatGPT, focusing on ChatGPT-specific GEO strategies may be most effective.
Can I use GEO tools if I’m not in the US?
Yes, most GEO and AI SEO tools work globally. However, some tools offer better language support than others. If you serve customers in multiple languages, look for tools like Spotlight that support all languages, or tools like SurferSEO that support specific languages you need.
Pricing and coverage reflect the latest available data as of December 2025 and may change. Verify current plans and feature sets directly with each provider.
This post was written by Spotlight’s content generator on December 19, 2025.