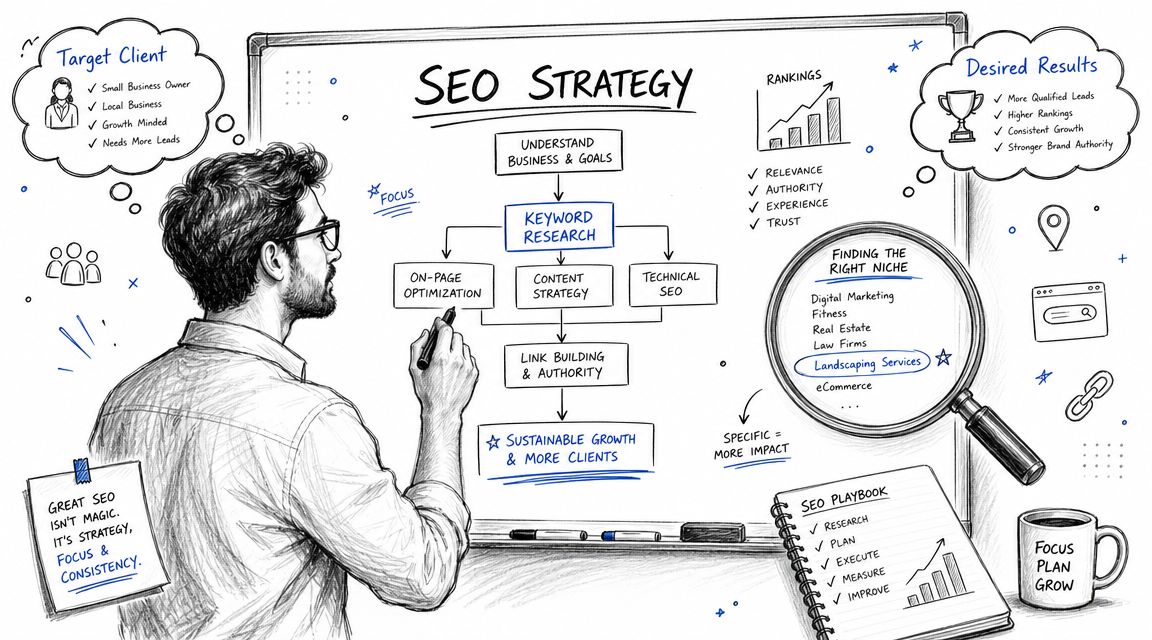
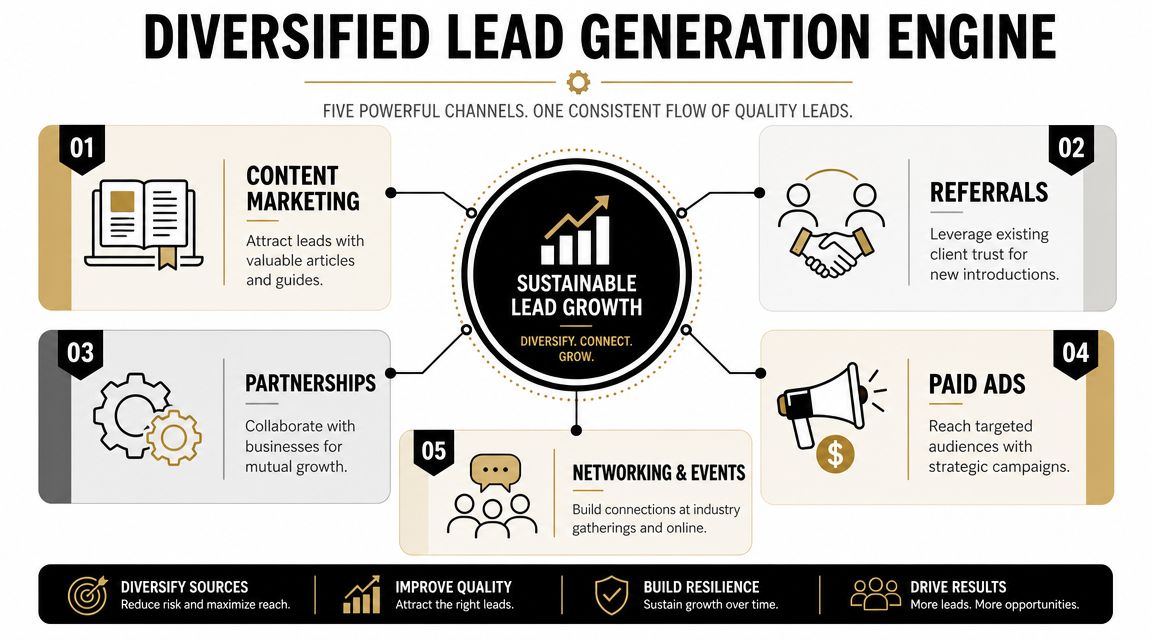
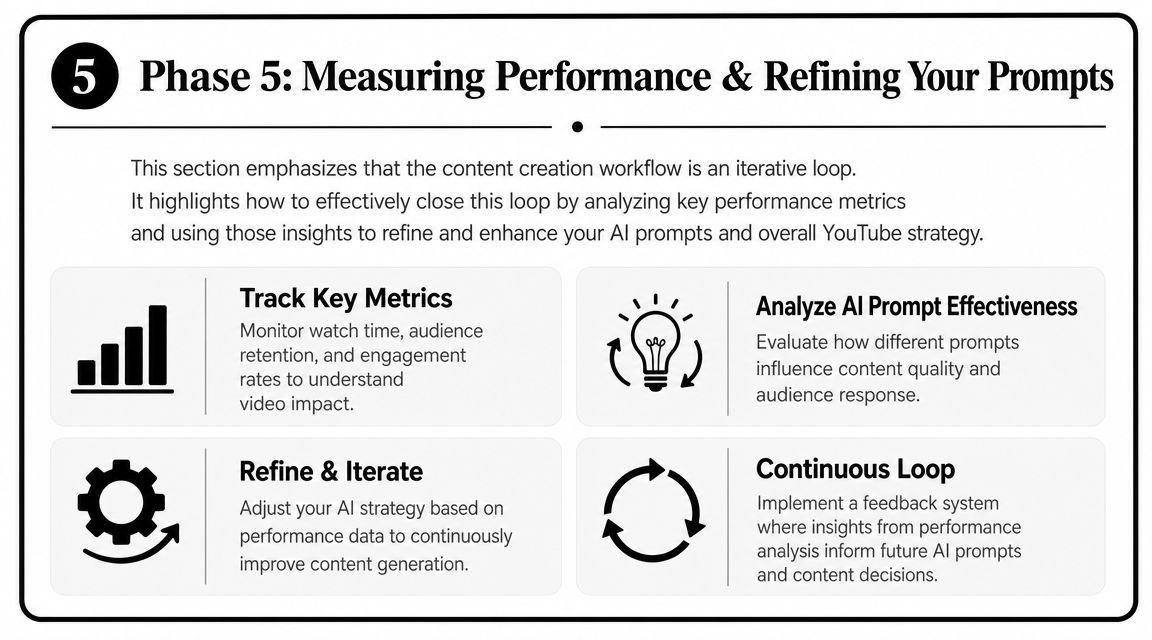
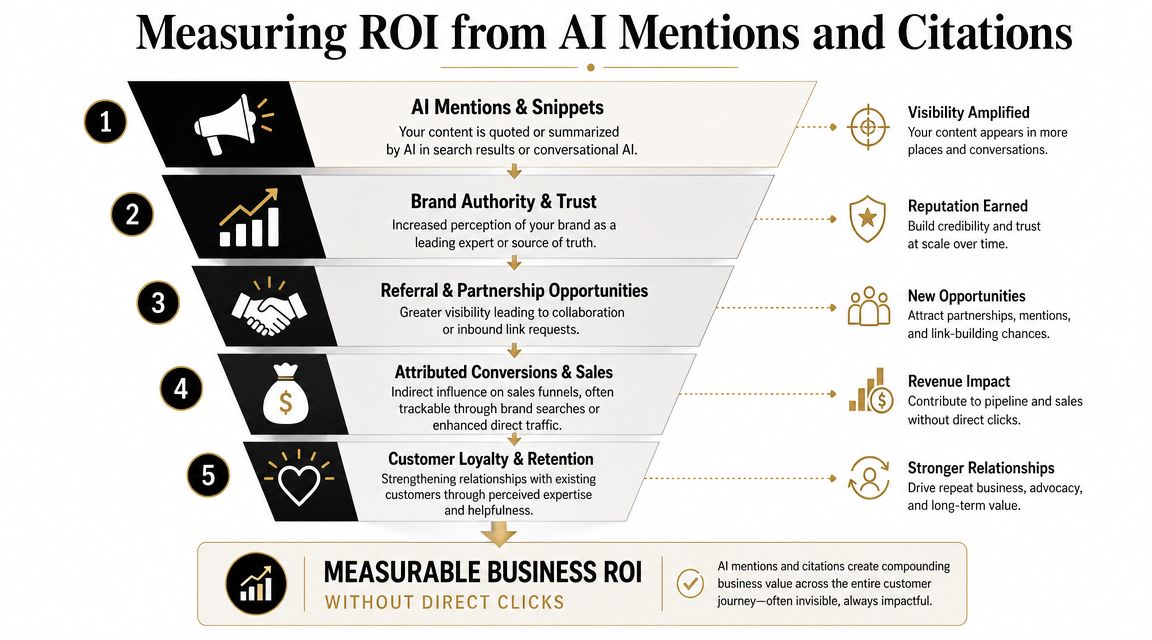
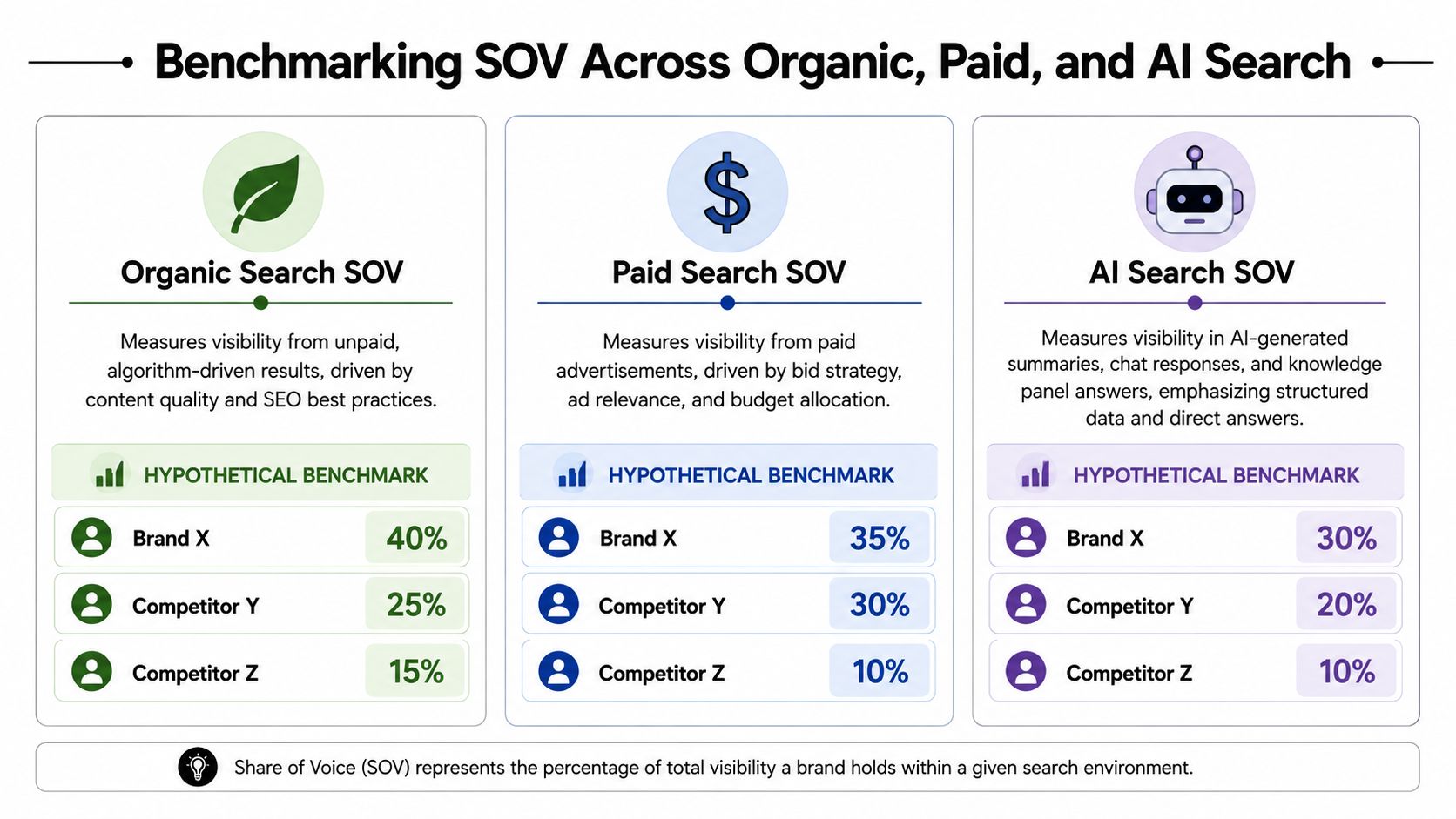
AI search is changing how consumers discover brands online.
AI assistant like ChatGPT, Claude, Gemini, and Perplexity provide the answers the users are looking for within their interface which means users are not as likely to visit a website. This change accelerated the rise in zero-click behavior where the users receive recommendations, product comparisons, and buying without ever clicking through to a source.
For marketers, this creates a significant challenge. SEO reporting relies on tangible metrics such as rankings, clicks, sessions, and conversions. However, AI search doesn’t necessarily follow the same path. A brand can be cited by AI assistants, influence purchasing decisions, and increase awareness without generating a single trackable visit.
As a result, many agencies can struggle to answer a critical client question: what is the ROI of AI search optimization?
The good news is that attribution is improving. Recent developments in Google Analytics 4 and specialist AI visibility platforms such as Spotlight will make it easier to measure the impact of AI search activity. However, proving ROI requires an evolution of existing reporting frameworks rather than relying solely on the metrics agencies have traditionally used.
How Do You Track ROI From AI Search?
For most digital marketers, measuring ROI in the channels they are targeting remains straightforward. Paid media campaigns are tied directly to clicks, conversions, and revenue, while SEO performance is often measured through rankings, organic traffic, leads, and sales.
However, AI search introduces an additional layer of complexity because many interactions occur within AI assistants themselves. For example, a user might ask ChatGPT for the best and then leave the conversation with a positive impression of the brand. But they might return a few days later through a branded search, direct visit, or referral from a colleague, in which case, AI search influenced the customer journey without being visible through attribution models.
Historically, the problem has been compounded by limited reporting. Traffic from AI platforms was often grouped with referral traffic or direct traffic, making it difficult to understand how much engagement was genuinely being driven by AI assistants.
That situation is beginning to improve.
Google Analytics 4 recently introduced an AI Assistant default channel grouping, giving marketers a clearer view of traffic originating from recognized AI platforms. This means that instead of relying on custom channel definitions or manual workarounds, agencies can now compare how AI-generated traffic performed in relation to other channels.
This allows marketers to better understand how visitors arriving from AI assistants engage with a website, which landing pages attract the most traffic, whether those users convert, and how AI-assisted journeys contribute to revenue over time.
While this is a significant step forward, traffic data alone doesn’t tell the full story.
One of the biggest differences between AI search and other acquisition channels is that visibility itself can have value. A brand may be cited in dozens of relevant AI responses before generating a measurable website visit. In some cases, the influence of those mentions may only become apparent later in the customer journey.
For that reason, agencies must broaden how they measure performance.
Reporting on AI search requires a change of mindset. Marketers must now think in terms of visibility, traffic, and business impact.
Visibility determines whether a brand is becoming more prominent within AI-generated responses. This includes factors such as citation frequency, prompt coverage, share of voice, and competitor visibility.
Traffic metrics help understand whether that visibility is translating into measurable website visits. GA4’s AI Assistant channel grouping provides an important layer of insight here, helping marketers evaluate engagement, landing page performance, and conversion paths.
Finally, both visibility and traffic must connect to business outcomes. These depend on the client so it could mean lead generation, sales enquiries, ecommerce revenue…
Looking at all three together creates a much more realistic picture of ROI than relying on traffic metrics alone.
How does Spotlight Helps Agencies Demonstrate AI Search ROI?
One of the most difficult aspects of AEO is understanding how systems respond to the user’s prompt.
Rather than evaluating a single prompt in isolation, the model expands that prompt into multiple related searches, entities, and concepts before generating a response.
For marketers, this creates both a challenge and an opportunity.
A client may have strong visibility for a primary topic but remain largely absent from the supporting concepts that influence recommendations. In other words, the brand is visible in some parts of the conversation but missing from others.
This is where Spotlight becomes particularly useful.
Its Fan-Out Queries feature helps agencies uncover the supporting searches AI systems use behind the scenes. By understanding these relationships, marketers can identify content gaps that would be difficult to uncover through keyword research alone.
In practice, this often reveals opportunities that weren’t obvious at the outset of a campaign. A software company, for example, may be focused on appearing for prompts related to its product category while overlooking adjacent topics that AI systems frequently reference when generating recommendations.
Spotlight’s Prompt Volumes feature helps solve another common challenge: prioritisation.
Knowing which prompts exist is useful, but agencies also need to understand which prompts are likely to drive meaningful visibility and commercial impact. Prompt volume data helps marketers focus their efforts on the conversations that matter most, rather than spreading resources across hundreds of low-value opportunities.
Perhaps the most important feature from a reporting perspective is Citation Tracking.
One of the biggest frustrations agencies face when discussing AI search with clients is that progress can be difficult to demonstrate. Rankings are visible. Traffic is visible. AI visibility has historically been far harder to measure.
Citation Tracking changes that by providing a way to monitor how frequently a brand is referenced across AI-generated responses. Agencies can track whether visibility is increasing, identify which prompts are driving citations, and compare performance against competitors.
This creates a far stronger reporting narrative. Instead of simply saying that content has been optimized for AI search, agencies can demonstrate that a client’s visibility is growing across commercially valuable prompts and that their share of voice is improving over time.
Even when referral traffic remains relatively modest, those insights provide tangible evidence that optimization efforts are moving in the right direction.
What Tools Should You Use To Optimize Content for AI Search?
As AI assistants become a more common discovery channel, marketers need ways to measure both visibility and performance.
Website analytics remains an essential part of reporting, but it cannot capture the full impact of AI search on its own.
For years, pageviews, rankings, referral traffic, and conversions formed the foundation of most SEO reporting frameworks. Those metrics still matter, but they were designed to measure activity that takes place after a user reaches a website. AI search introduces a new challenge because some of the most valuable interactions may happen before a visit ever occurs.
This is why many agencies are beginning to combine analytics platforms with specialist AI search tools.
GA4 should remain the foundation of any measurement strategy. The introduction of AI Assistant reporting gives agencies greater visibility into how much traffic is arriving from AI platforms and what happens once users reach the site. This data is invaluable when connecting AI visibility to measurable business outcomes.
However, analytics platforms are only one piece of the puzzle.
They can tell you what happened after someone visited the website, but they cannot tell you how often a brand is being recommended, which prompts are generating visibility, or whether competitors are gaining more exposure within AI-generated responses.
This is where Spotlight fills an important gap.
Its prompt intelligence, fan-out query analysis, citation tracking, and visibility monitoring features help agencies understand performance beyond traffic metrics. Rather than focusing exclusively on visits and conversions, marketers can build a broader picture of how clients are appearing across AI ecosystems.
The combination is particularly powerful. GA4 helps demonstrate the measurable outcomes generated by AI traffic, while Spotlight helps explain why those outcomes are happening and where future opportunities exist.
Together, they allow agencies to move beyond surface-level reporting and build a much more comprehensive view of AI search performance.
Conclusion
Demonstrating ROI from AI search optimization requires agencies to broaden how they measure success.
As zero-click behavior becomes increasingly common, clicks and sessions alone can no longer tell the whole story. Visibility, citations, prompt coverage, and share of voice are becoming important indicators of performance alongside traffic and conversions.
The introduction of AI Assistant reporting in Google Analytics 4 is an important step forward, but traffic data on its own only provides part of the picture.
To understand the full impact of AI search, agencies also need visibility data. They need to know where brands are being cited, which prompts are driving exposure, and how that visibility compares to competitors.
By combining analytics data with Spotlight’s prompt intelligence, fan-out query analysis, and citation tracking capabilities, agencies can build a more complete understanding of AI search performance and demonstrate meaningful ROI to clients.
The agencies that adapt their reporting frameworks now will be better positioned to prove the value of AI search optimization and help clients compete as AI becomes an increasingly important part of the customer discovery journey.
Most AEO analysis tools can tell you whether your brand appears in ChatGPT, Gemini, Claude, or Perplexity. However far fewer make that data accessible through an API. This is feature that is becoming increasingly important as businesses move beyond basic AI visibility reporting and begin integrating AI search data into dashboards, BI platforms, CRM systems, and internal analytics tools.
For agencies managing multiple clients, manually exporting reports isn’t scalable. For enterprise teams, it creates data silos that make it difficult to connect AI visibility with wider marketing performance.
As a result, API access is fast becoming one of the most important considerations when evaluating an AI search optimization platform.
WHY API ACCESS MATTERS FOR AI Search Optimization
Most marketers don’t need another dashboard. They need data that fits into the reporting systems they already use. They will, for example, need to pull visibility data into Looker Studio, build custom Power BI dashboards, or automate client reporting.
What Data Should An Ai Visibility Api Provide?
Not all AI visibility APIs provide the same level of detail. Some platforms provide little more than a visibility score and even it is useful to provide a headline metric, it won’t help explain why a brand appears in AI-generated answers or how to improve performance.
This means that marketers want more sophisticated APIs that expose citation data, source attribution, prompt performance, competitor visibility, and historical trends. Such insights are much more valuable and reveal the factors behind the recommendations.
SPOTLIGHT
potlight is arguably one of the strongest options for businesses that need both visibility reporting and API-driven automation.
While many AI visibility platforms focus primarily on dashboards, Spotlight’s API allows agencies and enterprise teams to integrate data directly into their reporting environments. This makes it particularly useful for organizations managing visibility across multiple brands, markets, or clients.
Another area where Spotlight stands out is citation analysis. Understanding whether your brand appears in ChatGPT is useful. Understanding why it appears is significantly more valuable.
PEEC AI
Peec AI takes a slightly different approach.
The platform places a strong emphasis on visibility measurement and reporting integrations, making it attractive for teams that want to operationalize AI search data across existing analytics workflows.
Compared with some competitors, Peec AI appears particularly focused on helping users connect AI visibility insights with broader marketing reporting rather than treating AI search as a standalone channel.
Profound
Profound remains one of the most recognized names in AI visibility monitoring, particularly among larger enterprise organizations.
The platform has built a reputation for comprehensive AI search reporting and competitive intelligence. For businesses with complex stakeholder requirements and sophisticated reporting structures, that level of depth can be attractive.
However, organizations evaluating Profound should pay close attention to the specific API functionality available and whether it aligns with their reporting requirements. Not every business needs enterprise-grade complexity, particularly if their primary goal is integrating visibility data into existing dashboards.
How APIs Support LLM Advertising Measurement
One of the biggest unanswered questions surrounding LLM advertising is measurement.
As AI platforms experiment with sponsored placements and commercial recommendations, marketers will need reliable ways to understand how paid visibility interacts with organic visibility.
APIs provide the infrastructure needed to answer those questions.
Choosing the Right GEO Tool for your Tech Stack
The best GEO tool isn’t necessarily the one with the largest feature list.
For some organisations, comprehensive citation data will be the deciding factor. For others, API flexibility will matter more than dashboard functionality.
The right choice depends on how AI visibility data will be used once it’s collected.
Final Thoughts
AI search reporting is moving in the same direction as SEO reporting did a decade ago. Visibility data is becoming more sophisticated, reporting requirements are becoming more demanding, and businesses increasingly expect data to flow seamlessly between platforms.
That’s why API access is becoming such an important differentiator.
Whether you’re evaluating Spotlight, Peec AI, Profound, or another AI visibility platform, the question isn’t simply whether the tool tracks mentions in AI search. It’s whether the data can be integrated into the systems your team already relies on.
As GEO, AEO, and LLM advertising continue to evolve, that distinction is likely to become even more important.
Your weekly SEO report is late again. The query that joins Search Console exports, CRM tags, and CMS metadata keeps hanging. At the same time, your AI visibility team is testing prompts to see whether ChatGPT, Gemini, or Perplexity mention the right brand, product, or category page, and the answers are inconsistent. One system is slow. The other is vague. Both problems come from the same root issue. You're asking a question that creates too much work, or not enough clarity, for the system answering it.
That's why optimizing a query matters far beyond the database team. For SEO and content teams, a good query is one that returns the right answer, in a useful shape, with as little wasted work as possible. In SQL, that means fewer rows scanned, fewer columns dragged through joins, and a plan the engine can execute efficiently. In AI, it means a prompt with enough structure and context that the model doesn't wander into irrelevant output or miss the entities you care about.
The useful mental shift is simple. Treat SQL queries and AI prompts as retrieval instructions. Both tell a system what to fetch, how to narrow scope, and what output format to produce. When teams adopt that shared discipline, they stop thinking of query tuning as a niche backend concern and start using it as an operating habit for analytics, content strategy, and AI search visibility.
A bad query rarely looks dramatic. It looks ordinary. A dashboard spins longer than expected. A report pulls duplicate rows. An AI prompt returns a polished answer that still ignores the brand comparison you needed.
For SEO teams, the cost shows up as delayed decisions. If your content cluster report arrives after the editorial meeting, it's less useful no matter how accurate it is. For AI visibility work, the cost shows up as false confidence. You may think a model “doesn't cite us” when the underlying issue is that your prompt asked for broad commentary instead of a constrained comparison, citation summary, or brand mention check.
A good query isn't just fast. It's clear, selective, and aligned to the task. If the task is to compare organic landing pages for one content cluster, the query should say that directly. If the task is to assess how an AI model talks about your brand in category-level prompts, the prompt should define the category, the brands, the response format, and the exclusions.
Practical rule: Optimize for correctness first, then for cost.
That principle holds across databases and AI systems. A sloppy SQL query can waste compute on unnecessary scans. A sloppy prompt can waste tokens on generic exposition. In both cases, the answer arrives slower and with more cleanup required downstream.
The teams that get this right don't separate “data work” from “AI work.” They use the same discipline in both places. Define the question. Reduce ambiguity. Remove unnecessary work. Then inspect the system's behavior before making changes.
Start with a Well-Formed Question
The fastest way to improve performance is often to stop asking vague questions. Teams usually reach for tuning after they've already written a messy query or prompt. That's backward. Most of the waste starts at formulation.
What clarity looks like in SQL
SQL gets slow and fragile when it asks for more than the task needs. The classic example is SELECT *. It feels convenient, but it tells the engine and your downstream workflow to carry every available column, whether you need them or not.
If an SEO analyst wants organic sessions, landing page, publish date, and content cluster for a single quarter, that request should look like this in spirit:
Specify only needed columns
Filter to the date range early
Join only the dimension tables required for the answer
Use readable aliases
Return a result set designed for the next step, not for curiosity
A rough example:
SELECT
gsc.landing_page,
gsc.organic_clicks,
cms.publish_date,
cms.content_cluster
FROM gsc_pages gsc
JOIN cms_pages cms
ON gsc.url = cms.url
WHERE gsc.report_date >= '2025-01-01'
AND gsc.report_date < '2025-04-01'
AND cms.content_cluster = 'technical-seo';
That query is easier to optimize because its intent is visible. You can inspect the join, the filters, and the projected columns quickly. The same mindset also improves collaboration. Analysts, engineers, and SEO managers can all see what the query is trying to answer.
If you're refining how you define search topics before they ever reach SQL, Netco Design's keyword strategy is a useful reference because it forces clearer scope around topic clusters, intent, and priority terms.
What clarity looks like in AI prompts
AI prompts fail for many of the same reasons SQL queries fail. They're too broad, they request too much output, or they leave key constraints unstated.
A weak prompt:
Analyze our competitors and tell me how we compare in AI search.
A stronger prompt:
Act as an SEO analyst. Compare brand mentions for Brand A, Brand B, and Brand C across category-level buying-intent prompts for enterprise CRM software. Return a markdown table with columns for brand named, context of mention, whether a citation appears, and notable omissions. Exclude social commentary and focus on product-selection intent.
That second version does several things well:
Assigns a role so the model knows the lens.
Defines the comparison set instead of leaving “competitors” open-ended.
Constrains the prompt type to category-level buying intent.
Specifies the output format so the answer is easier to audit.
Adds exclusions to reduce irrelevant text.
Good prompt engineering is often just query optimization with natural language instead of SQL syntax.
For content teams, one of the most useful habits is to draft prompts and SQL side by side. If your prompt asks for “brand visibility by topic,” your SQL should already reflect what “brand,” “visibility,” and “topic” mean in your reporting model. That keeps both systems aligned and makes debugging much easier later.
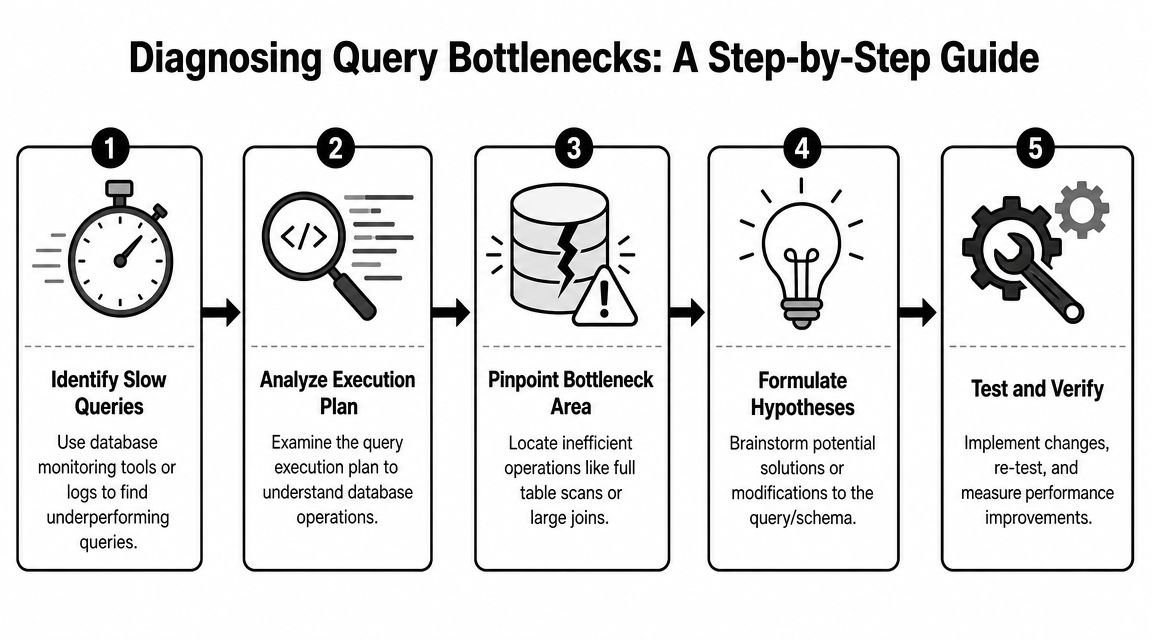
How to Diagnose a Performance Bottleneck
When a query turns slow, teams often change syntax immediately. They add an index request, rewrite a join, or split the query into pieces before they've identified where the actual cost sits. That's how tuning turns into superstition.
Read the plan before changing the query
A practical workflow starts with the execution plan, then moves to early filtering, then reducing row and column width before joins. Snowflake's guidance emphasizes inspecting plans for full scans, large shuffles, or expensive joins before production deployment, along with tactics like using WHERE instead of HAVING, avoiding SELECT *, and joining smaller tables first in the logical design of the query, as described in Snowflake's query optimization overview.
In plain terms, the plan tells you how the engine intends to do the work. You're looking for signs that the engine is reading much more data than expected or combining tables in an expensive way.
Common red flags include:
Full scans on large tables when the query should be selective
Expensive join operations on wide intermediate results
Large movement of data between processing stages
Late filters that allow too many rows into the join step
Aggregations after unnecessary expansion of the row set
A second issue is less visible but often decisive. Modern database engines use a cost-based optimizer that selects an execution plan based on statistics about tables and indexes. Oracle explicitly notes that collecting statistics on base tables improves query performance and that these statistics cover the table's columns and associated indexes, while IBM and Snowflake make the same broader point about optimizers relying on current statistics to estimate cost accurately in Oracle's documentation on optimizing queries with statistics.
That matters because a query can be logically fine and still degrade after data changes. If statistics are stale, the optimizer can misjudge row counts and choose a plan that scans far more data than necessary.
A query that suddenly becomes slow often didn't “break.” The optimizer lost sight of the data distribution it was planning against.
Use a parallel diagnostic loop for AI
AI prompt diagnosis follows the same pattern, even though the tools differ. Don't rewrite everything at once. Strip the prompt down and identify which instruction adds confusion, delay, or off-target output.
A practical loop looks like this:
Check
Database query
AI prompt
Scope
Are too many tables or dates included?
Are too many tasks packed into one prompt?
Selectivity
Are filters applied early?
Are constraints and exclusions explicit?
Output width
Are unused columns returned?
Is the model asked for too much prose?
Planner behavior
Does the execution plan show scans or costly joins?
Do repeated tests show the model ignoring one instruction?
For AI workflows, isolate variables one at a time:
Remove extra tasks such as “analyze, summarize, recommend, and rewrite”
Reduce output format complexity
Fix the comparison set
Test whether brand names, product names, or query classes are too ambiguous
Review logs or saved runs to see whether the same prompt shape fails consistently
One undercovered reality is that generic advice doesn't explain every bad plan. Engine-specific behavior can matter. SQL Server practitioners have pointed out that some subquery plans become suboptimal in ways that generic indexing advice won't fix, and that changing query shape can matter more than adding another broad tuning tip, as discussed in Erik Darling's analysis of subquery plans in SQL Server.
That has a clear AI parallel. Sometimes the prompt isn't wrong in content. It's wrong in shape. The model may respond better to a two-step sequence than one overloaded instruction. Diagnosis starts by observing actual behavior, not by applying canned fixes.
Core Techniques for Faster Queries
The most durable rules in query tuning haven't changed much because the main costs haven't changed much either. Filter early, project less, and join efficiently remain the foundation across platforms because they directly reduce the work involved in reading and processing data, as summarized in Dremio's SQL query optimization guidance.
Filter early and narrow the workload
If your SEO warehouse stores page performance, keyword mappings, and editorial metadata, the cheapest row is the row you never read.
A weaker pattern:
SELECT
p.*,
k.*,
c.*
FROM page_metrics p
JOIN keyword_map k ON p.url = k.url
JOIN content_meta c ON p.url = c.url
HAVING c.content_type = 'blog';
A better pattern pushes the filter into WHERE and narrows the candidate set before the heavy join work expands:
SELECT
p.url,
p.organic_clicks,
c.content_cluster
FROM page_metrics p
JOIN content_meta c ON p.url = c.url
WHERE c.content_type = 'blog';
In AI prompt terms, filtering early means adding negative constraints and scope limits up front. If you want brand mention analysis for commercial-intent prompts, say that immediately. Don't ask for “all visibility patterns” and hope the model infers the commercial angle.
Useful translations from SQL to prompts:
SQL WHERE clause becomes prompt constraints
Date filter becomes timeframe or scenario boundary
Entity filter becomes explicit brand or topic inclusion list
Project less and control output shape
Projection is one of the easiest wins because teams often over-request data out of habit. They pull every column “just in case,” then sort out relevance later in Python, Sheets, or BI.
That's expensive in databases and messy in AI. In SQL, unnecessary columns increase row width and can make joins, sorts, and memory use heavier. In AI, unnecessary output requirements encourage the model to produce filler.
Field note: If you can't explain why a column or output section is needed before running the query, remove it.
For AI prompts, projection control means specifying the result shape tightly:
Use markdown tables when you need comparability
Ask for bullets when you need scanning
Request short evidence-backed observations, not essays
Set boundaries such as “return only categories, cited sources, and missed entities”
For SEO analysts doing entity and citation review, tooling is helpful. If you need visibility into the search queries models branch into before citing sources, the Spotlight Query Fan-Out extension is useful because it reveals the fan-out queries used in AI search workflows. That gives content teams a concrete way to compare what they think they're asking with what the system is retrieving.
If your team is also sharpening topic selection upstream, effective keyword analysis methods can help clarify which terms belong in the retrieval layer versus the reporting layer.
Join efficiently and question the request pattern
Joins create value, but they also create risk. The common advice is solid. Use indexes on columns involved in WHERE, JOIN, and ORDER BY clauses. Prefer smaller or indexed joins. Remove unnecessary joins. Break complex logic into CTEs when that reduces work. The nuance is that not every slow query is rescued by another index or cleaner syntax.
A useful habit for SEO data work is to ask whether the join belongs in the same query at all. If you're joining raw GSC page rows, keyword mappings, CMS metadata, author info, and internal linking data just to produce a weekly editor summary, you may be building a monolith where a staged workflow would be simpler and more reliable.
Consider this decision frame:
Keep it in one query when the logic is clear and the result is consumed once
Stage it into steps when intermediate datasets are reusable or significantly smaller
Precompute common shapes when the same expensive combination gets queried repeatedly
There's also an application-level challenge people miss. Some workloads create avoidable cost before the database even sees the SQL. If the app forces wildcard search across a broad dataset or triggers repeated N+1-style lookups, the database inherits unnecessary work. In those cases, “optimizing a query” starts with redesigning the request pattern, not shaving syntax.
For AI, the equivalent is a prompt chain that repeatedly asks for the same retrieval context in slightly different wording. If you can cache the context, separate retrieval from synthesis, or reduce repeated lookups, you cut cost and improve consistency at the same time.
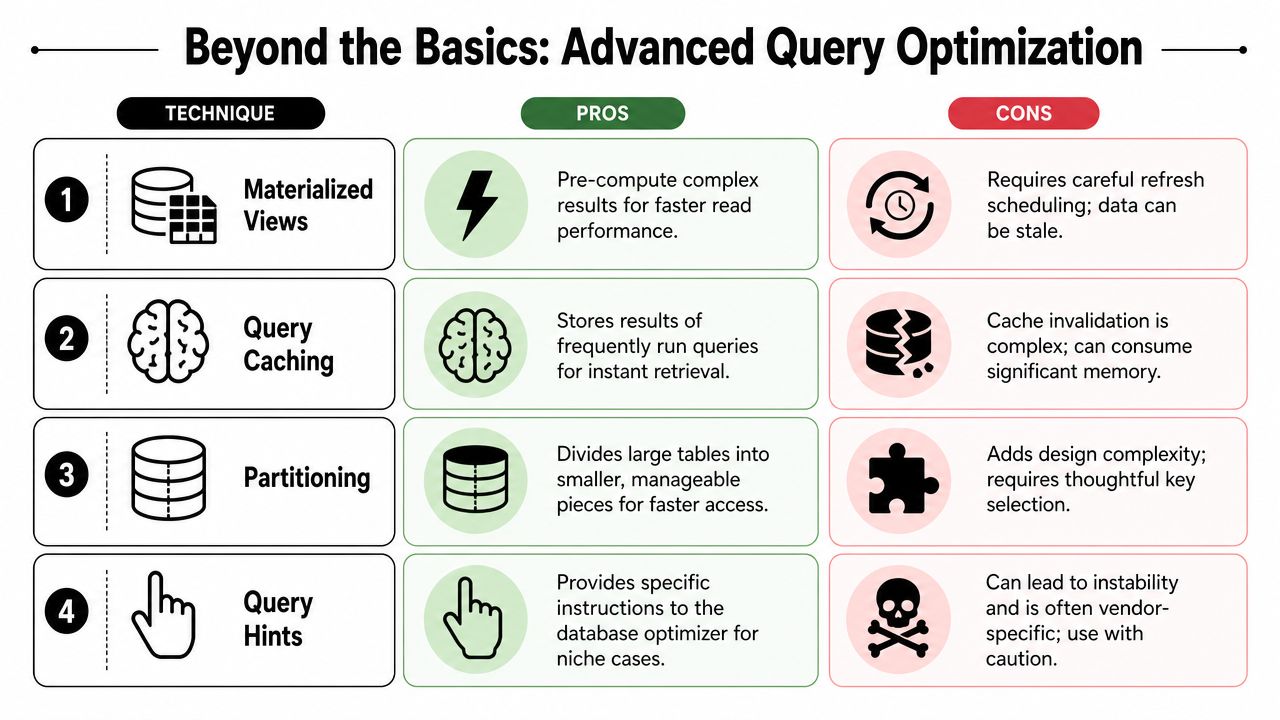
Advanced Strategies Beyond Basic Syntax
Basic tuning gets you far, but the next layer of gains usually comes from architecture and experimentation rather than clever SQL alone.
When the application is the real bottleneck
One of the most overlooked optimization moves is to stop tuning the query and change the request pattern instead. SQL Server guidance makes this point clearly when discussing wildcard searches and related techniques. If the application insists on broad string matching or repeated lookups, it can create unavoidable work that no amount of SQL polishing will fully remove, as outlined in SQLShack's query optimization techniques.
That lesson applies directly to AI search workflows. Many teams ask a model to do retrieval, comparison, narrative synthesis, sentiment framing, citation extraction, and recommendation generation in one pass. The prompt isn't just long. The task graph is badly designed.
Here are common situations where changing the pattern beats tweaking syntax:
Repeated lookups If your application asks for page-level metrics one URL at a time, consolidate requests upstream.
Monolithic prompts Split retrieval from evaluation when the model keeps mixing evidence gathering with opinion.
Wildcard or fuzzy search by default Narrow the candidate set first, then apply fuzzy logic only where needed.
Heavy joins for recurring reports Consider materialized views, temporary tables, or cached intermediate tables when the same combination is requested repeatedly.
A query that's fast on one engine may still be slow on another. Join choice, row goals, and optimizer behavior differ. Hints can help in edge cases, but they come with maintenance risk and lock you into vendor-specific behavior. Use them carefully, and only after you've confirmed the planner keeps making a bad choice for a stable workload.
Sometimes the right optimization is to stop asking one giant question and start asking two precise ones.
For teams adapting SEO workflows to AI search, SEO for generative AI search is a useful companion read because it pushes the conversation beyond classic rankings into how models retrieve, summarize, and cite information.
How to test advanced changes without guessing
Advanced optimization needs proof, not folklore. If you're comparing a materialized view against a base-table query, or a single-prompt workflow against a two-step AI chain, define the test before you implement the fix.
Use a simple evaluation setup:
Hold the business question constant
Change one design variable at a time
Run the same workload repeatedly
Record the behavior in a shared log
Review trade-offs beyond speed, including freshness, maintenance burden, and result quality
A compact scorecard helps:
Change tested
What improved
What got harder
Materialized view
Faster recurring reads
Refresh management
Query cache
Faster repeated access
Invalidation logic
Query hint
Better plan in niche case
Portability and stability
Two-step prompt flow
Cleaner outputs
More orchestration overhead
This is also where stakeholder trust is won. When a content lead asks why engineering is spending time on “query refactors,” the answer should be grounded in workflow outcomes. Faster reports, cleaner joins between content and performance data, and more stable AI evaluation runs are much easier to defend than abstract claims about elegance.
Measuring Success and Proving Value
Optimization work only matters if someone can tell the difference without reading the SQL.
Measure the system, not just the syntax
For databases, compare the old and new versions of the same query under the same business question. Track practical indicators such as runtime, data scanned, shuffle behavior, full scans observed in the plan, and whether the result set shape is easier for downstream analysis.
For AI prompts, compare prompt versions against a fixed evaluation set. Measure whether the output is more relevant, more constrained, easier to parse, and more faithful to the task. If you're monitoring AI search visibility, define what counts as a useful result before testing. Brand mention presence, citation capture, prompt class coverage, and consistency across repeated runs are all more useful than a vague “better answer” label.
A clean reporting habit is to keep one worksheet or dashboard with three layers:
Technical metric such as latency or plan quality
Workflow metric such as report turnaround or analyst review time
Business metric such as campaign decisions made faster or AI visibility checks completed reliably
If your team is evaluating AI search demand, prompt volume in AI search is worth understanding because it helps separate prompt frequency from anecdotal prompt examples.
Tie speed improvements to business outcomes
The strongest optimization stories don't end with “the query runs faster now.” They end with a business change.
Examples include:
Editorial teams get a weekly cluster report in time for planning
Analysts spend less time cleaning unnecessary output
AI visibility reviews become repeatable instead of ad hoc
Brand and content teams can compare model mentions using the same structure each cycle
This is why optimization should be treated as an ongoing discipline. Data changes. Content inventories grow. AI systems shift in how they retrieve and summarize. A query or prompt that worked last quarter can drift out of fit even when nobody touched the syntax.
The teams that keep performance high don't rely on one heroic cleanup. They build a review loop. They inspect plans. They simplify prompts. They remove unnecessary joins and unnecessary instructions. They test changes against real tasks, then keep what holds up in production.
Building a Culture of Performance
Teams get better at optimizing a query when they stop treating it as a rescue move. It needs to be part of how analysts write SQL, how content teams frame research requests, and how AI visibility programs evaluate prompts.
That culture starts with a simple standard. Every question should be clear, scoped, and cheap enough to answer responsibly. In practice, that means better query formulation, regular inspection of real system behavior, and a willingness to redesign the request pattern when syntax changes aren't enough. For teams adapting SEO workflows to newer systems, using AI in search engine optimization is part of the same operational shift.
Spotlight Group LLC helps teams monitor how brands appear across AI search and conversations, including which prompts surface them, which sources models cite, and how visibility changes over time. If your team is trying to connect classic query discipline with AI search performance, Spotlight Group LLC is one option to evaluate alongside your existing analytics and content workflow.
The most repeated advice about H1 tags is also the least useful: “Use one H1 with your exact keyword and you're optimized.”
That's outdated. A good H1 still matters, but not because it acts like a ranking cheat code. It matters because it tells people, crawlers, screen readers, and now AI systems what the page is about. In practice, H1 tag SEO has shifted from tactical keyword placement to clear semantic labeling.
That shift changes how content teams should work. If your H1 is vague, stuffed, or disconnected from the rest of the page, you make the page harder to interpret. If it's clear, aligned with the title tag, and supported by a clean heading hierarchy, you give both search engines and AI summarization systems a better shot at understanding the page correctly.
The old myth says the H1 is a major ranking lever on its own. The evidence no longer supports that framing.
What still holds true is that the H1 is one of the clearest ways to define a page's topic. It's not a strict requirement for ranking by itself, but it remains one of the strongest page-level signals for what the document is about when it's used well. That matters for SEO, accessibility, and AI-driven summarization.
A lot of teams still overinvest in the wrong part of H1 optimization. They debate exact-match phrasing, force awkward wording, and treat the heading like a place to stuff search terms. That usually weakens the page. A robotic H1 doesn't help readers trust the content, and it doesn't improve the broader structure that modern systems use to interpret meaning.
The real job of the H1
A strong H1 does three jobs at once:
Sets topic expectation: It tells a visitor what they're about to read.
Supports structure: It anchors the hierarchy that H2s and H3s build underneath.
Improves machine interpretation: It gives crawlers and AI systems a high-confidence label for the page's main subject.
Practical rule: Treat the H1 as the page's top-level topic statement, not as a keyword container.
H1 tag SEO becomes more important in 2026, not less. Traditional ranking impact may be less rigid than people think, but semantic clarity matters more because content now needs to be understood not only for indexing, but for extraction, summarization, and citation.
What works and what doesn't
What works is simple: write a heading that clearly names the page topic in natural language and matches the rest of the content.
What doesn't work is writing something like “Best H1 Tag SEO Keyword Strategy for H1 Tag SEO Success” and expecting that repetition to send a stronger signal. That style belonged to an older search era. Today, the better move is clarity, consistency, and usable structure.
Understanding the H1's Semantic Role
An H1 is the main heading of the document. That sounds basic, but the important part is semantic, not visual. An H1 isn't just bigger text. It's a structural signal that tells systems, “this is the main topic of the page.”
Think of the H1 as the book title
The easiest way to explain it to a content team is with a book analogy.
The H1 is the book's title. Your H2s are the main chapters. Your H3s are the sub-sections inside those chapters. If the book title is unclear, every chapter underneath it becomes harder to interpret. The same thing happens on a webpage.
That structure matters to more than Googlebot. Screen readers rely on heading markup to help people move through content quickly. A clean heading hierarchy lets someone jump to the section they need instead of listening to the entire page line by line. When teams use headings only for styling, they break that experience.
According to Moz's guide to H1 tags, Google and other search engines use the H1 as a strong page-level signal for the document's main topic, but it isn't a strict ranking requirement. Pages can still rank with multiple H1s or even no H1s if the content satisfies intent and is well structured.
Why semantics matter in practice
That flexibility is where people get confused. They hear “Google can rank pages without an H1” and conclude that H1s don't matter. That's the wrong takeaway.
An H1 still reduces ambiguity. It helps a crawler classify the page faster. It helps a reader confirm they landed in the right place. It helps assistive technologies present the page properly. And in AI search environments, it gives models a clean opening signal about the document's central topic.
Here's what a semantic H1 does well:
Names the topic directly: “H1 Tag SEO Guide for 2026” is clearer than “Everything You Need to Know.”
Matches user intent: The heading should reflect what the page answers.
Supports hierarchy: The sections below should logically expand the promise of the H1.
A poor H1 usually fails in one of two ways. It's either too generic to be useful, or it's overloaded with keywords in a way no person would naturally write.
A heading can be technically valid and still be strategically weak.
That's the distinction teams need to understand. Semantic usefulness is the standard now.
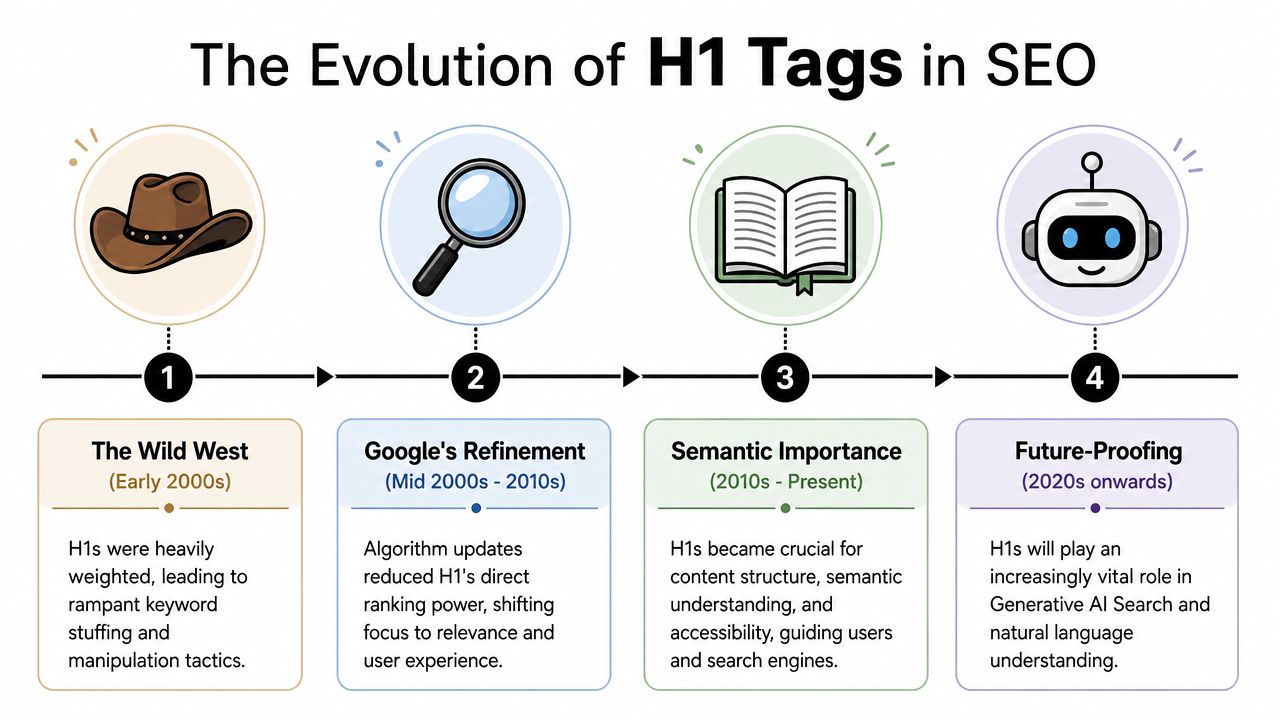
The Evolution of H1 Tags in SEO
H1 guidance only makes sense if you understand the history. A lot of bad advice survives because it was once directionally right in a very different search environment.
What changed from old SEO to modern SEO
In the early era of SEO, teams treated the H1 as a high-value ranking element. That led to predictable abuse. Marketers stuffed exact-match keywords into H1s, repeated phrases unnaturally, and often wrote headings for algorithms instead of people.
Google's evolution changed that.
As documented in Moz's H1 experiment and discussion of Google guidance, John Mueller said in 2019 that a site can rank well with no H1 tags or with five H1 tags, and that multiple H1s are normal in HTML5. The same Moz analysis also reported no statistically significant ranking difference between pages using H1s and H2s for titles. That was a major correction to the old one-H1-or-fail mindset.
The takeaway isn't that structure stopped mattering. It's that strict H1 formulas lost direct ranking importance as search systems became better at understanding context, semantics, and intent across the full page.
The H1 used to be treated like a shortcut. Now it works more like a label in a larger system of meaning.
That larger system includes body copy, internal linking, title tags, schema, layout, supporting headings, and the overall coherence of the document. Teams that still optimize H1s in isolation are solving the wrong problem.
What that means for teams today
The modern best practice is more flexible, but also less forgiving of sloppy writing. You don't need to obsess over rigid old-school rules. You do need a heading that makes sense for humans and fits the rest of the page.
For technical teams working across templates, CMS limitations often create the actual H1 problems. Theme output, component libraries, and page-builder defaults can all introduce structural noise. If you're thinking about AI search readiness, this broader foundation matters as much as the headline itself. A useful companion read is this guide to technical foundations for ranking on AI search.
The shift is simple. Old SEO asked, “Did we place the keyword in the H1?” Modern SEO asks, “Is the page easy to understand at a glance?”
How to Write an Optimized H1 Tag in 2026
Most H1 advice is either too rigid or too loose. The practical middle ground is better. Use one clear H1 in most cases, write it in natural language, align it with the page title and topic, and make sure the section hierarchy underneath it is clean.
A useful data point supports that approach. A 2026 Rankability case study on H1 usage found that 93.5% of top-ranking pages used a single H1 tag, but it also found a negligible correlation of −0.0282 between rank and partial keyword match in the H1. That's the clearest summary of modern H1 tag SEO I've seen. Top pages usually use one H1, but keyword matching inside the H1 doesn't show meaningful ranking power on its own.
The modern H1 checklist
Use this as an editorial standard.
Write for topic clarity: The H1 should tell a first-time visitor exactly what the page covers. If someone can't understand the subject from the heading alone, rewrite it.
Keep it aligned with the title tag: It doesn't have to be identical, but it should describe the same topic in closely related language.
Include the primary keyword naturally: If the main phrase fits, use it. If exact-match wording sounds forced, choose the clearer version.
Use one H1 on most pages: HTML5 allows more flexibility, but one main heading still creates the cleanest structure in most CMS environments.
Make the supporting hierarchy logical: H2s should break the main topic into major sections, and H3s should sit under the relevant H2s only.
For teams managing enterprise CMS environments, implementation often matters as much as copy. If you work in Sitecore or SharePoint, Kogifi on Sitecore and SharePoint SEO is a practical reference because these platforms often create heading issues through templates rather than through editorial intent.
A simple implementation example
Here's the pattern you want:
<h1>H1 Tag SEO Guide for Search in 2026</h1>
<h2>Why H1s Still Matter</h2>
<h2>How to Write a Strong H1</h2>
<h3>When to Use the Primary Keyword</h3>
<h2>Common Mistakes</h2>
And here's the pattern you want to avoid:
<h1>SEO</h1>
<h3>Tips</h3>
<h2>H1 Tag SEO H1 Tags Best SEO H1</h2>
The first example creates a usable outline. The second creates confusion.
If you want a good editorial test, read the H1 and all H2s without reading the body copy. If the outline feels coherent, you're probably in good shape. That same principle also supports AI extraction, because readable structure makes the page easier to summarize accurately. This is one reason teams focused on AI visibility also care about readability levels that win GEO and AEO citations.
Most H1 problems aren't conceptual. They're operational. A CMS strips the heading. A template outputs multiple H1s. A designer uses an H1 for a logo. A writer publishes a clever headline that says nothing.
The fix is usually straightforward if you look at the page like a structure problem, not just a copy problem. As noted by MarTech's H1 best practices overview, the highest-value pattern is keeping the H1 semantically aligned with the page's title and primary keyword while maintaining a clean H1 → H2 → H3 hierarchy so crawlers and accessibility tools can interpret the content properly.
H1 Tag Error Correction Guide
Mistake
Why It's a Problem
How to Fix It
Missing H1
The page has no clear top-level topic marker
Add one visible main heading that accurately describes the page
Multiple H1s from a theme or builder
The page may present several competing main topics
Keep one primary H1 and convert the others to H2 or styled text
Logo wrapped in H1 on every page
The site brand becomes the main heading instead of the actual page topic
Reserve the H1 for the page title, not the header logo
Vague heading such as “Welcome” or “Resources”
Users and crawlers get little context about the page's purpose
Replace it with a descriptive phrase tied to actual intent
Keyword-stuffed H1
The heading reads unnaturally and weakens usability
Rewrite it in plain language and keep only the relevant phrasing
H1 misaligned with title tag
The page sends mixed signals about the main topic
Bring the title tag and H1 into close topical alignment
Heading levels skipped below the H1
The outline becomes harder for assistive tools and crawlers to interpret
Use a logical order, starting with H2 for major sections
Hidden H1 used only for SEO
Users see one message while the markup signals another
Use a visible H1 that matches the page's true topic
A quick review standard
When reviewing pages, ask three questions:
Can a human identify the topic instantly
Does the heading outline make sense in order
Does the page promise match the page content
If the answer to any of those is no, the H1 probably needs work.
H1 Tags and the Future of AI Search
The next phase of H1 tag SEO isn't about ranking formulas. It's about interpretation quality.
AI search systems don't read pages the way a person does. They parse, compress, and assemble meaning from multiple signals. In that process, the H1 functions like a high-priority label for what the document is trying to say. If the label is vague, bloated, or disconnected from the content below it, the system has to infer more. That increases the risk of a weak summary or a bad citation context.
Why AI systems care about H1 clarity
The old “exact match everything” advice breaks down. The more useful question is whether your H1 makes the page easy to summarize accurately.
According to Mangools' discussion of H1 SEO, guidance is inconsistent on whether the H1 still needs exact-match keyword optimization. Many pages rank well with more natural, user-first H1s, which suggests that over-optimizing the H1 is less valuable than aligning it with the overall page structure for AI and user clarity.
That matches what content teams are seeing in practice. Cleanly written headings tend to support cleaner extraction. Messy headings force models to reconcile conflicting signals from titles, intros, subheads, and body copy.
If a model has to guess what your page is about, your H1 has already failed its first job.
What to optimize for now
For AI search and generative engine optimization, a strong H1 should do four things:
Name the subject plainly: Use the language your audience expects, not brand-speak.
Match the content underneath: Don't promise a guide if the page is a product page, and don't label a comparison page like a tutorial.
Support likely summaries: If an AI system had to describe your page in one sentence, the H1 should help it get that sentence right.
Reduce ambiguity across templates: This is especially important in CMS-heavy sites and WordPress builds where theme issues can damage semantic structure. For teams cleaning that up, this guide to avoiding WordPress SEO errors is useful because many heading problems start in templates, not in copy.
AI visibility work also benefits from understanding how content gets interpreted and reused by generative systems more broadly. This article on search engine optimization using AI is a good next read if your team is connecting on-page SEO to GEO strategy.
The H1 hasn't become more powerful because of keyword weighting. It has become more strategic because more systems now depend on fast, reliable topic extraction.
Frequently Asked Questions About H1 Tags
What's the difference between a title tag and an H1
The title tag is the page title that typically appears in search results and browser tabs. The H1 appears on the page itself as the main visible heading. They should usually be closely aligned, but they don't have to be identical word for word.
Should you use emojis or special characters in an H1
Usually, no. A few brands can make it work, but most pages benefit from plain language. Special characters often make headings look less professional and can distract from the core topic signal.
What's the fastest way to audit H1 tags across a site
Use a crawler such as Screaming Frog to export heading data at scale, then spot-check key templates in the live browser. Also inspect the rendered HTML, because page builders and JavaScript can create heading problems that aren't obvious in the editor.
Spotlight Group LLC helps brands understand and improve how they appear across AI search platforms. If your team wants to see where models mention your brand, which prompts trigger those mentions, and what content earns citations, Spotlight Group LLC is built for that workflow.
Most advice about a keyword rankings and visibility report is outdated. It still assumes the report's job is to tell you whether a keyword moved from one position to another in Google.
That's too narrow now.
A useful report has to answer a harder question: where is your brand gaining or losing visibility across search surfaces, prompt types, geographies, and user intent? If you only track blue-link rankings, you can miss a more serious shift. A page can hold steady in traditional search while your brand disappears from AI answers, loses featured snippet exposure, or weakens in the specific markets that drive pipeline.
The reporting mistake isn't just old tooling. It's old framing. Search visibility is no longer one metric, one engine, or one audience.
A traditional keyword report usually answers the wrong question. It tells you what rank changed. It doesn't tell you which segment lost visibility, which intent bucket weakened, which geography slipped, or which terms fell out of meaningful range entirely.
That gap matters because modern visibility isn't a single-position metric. Advanced Web Ranking's analysis makes the point clearly: the more useful question isn't “what rank changed?” but “which ranking-band segment lost ground, and which keywords fell out of top 100 entirely,” while also breaking out topic clusters, geography, and intent in the analysis keyword ranking distribution workflow.
Rankings alone hide business risk
If your report shows that average positions stayed stable, that can sound fine. It often isn't.
A portfolio can look healthy at the headline level while high-value commercial terms drift downward, informational terms improve without driving revenue, or one country weakens while another masks the loss. Add AI answer surfaces to that mix and the blind spot gets larger. People don't always visit a ranked page now. Sometimes they get the answer before the click.
Practical rule: If your report can't isolate changes by ranking band, intent, geography, and topic cluster, it can't diagnose the cause of visibility loss.
The same problem exists inside analytics. Many teams still try to interpret organic performance with incomplete query data, then fill the gaps with assumptions. If your search reporting is already constrained by missing keyword data, a practical guide to 'not provided' analytics is worth reviewing before you redesign the report. It helps clarify what you can infer responsibly and what you can't.
Visibility now spans multiple surfaces
A page can rank. A brand can still lose.
That happens when competitors capture featured snippets, local packs, AI-generated answers, or citation share in prompts related to your category. Traditional rank tracking remains useful, but only as one layer. The report has to connect ranking movement with actual exposure and business relevance.
Use this test. If your current keyword rankings and visibility report can't answer these questions, it's incomplete:
Which keyword groups lost exposure by intent? Informational decline and commercial decline are not the same problem.
Which geographies changed first? National stability can hide regional weakness.
Which topics are weakening even when average rank looks flat? Distribution matters more than a single average.
Which channels still show you and which don't? Traditional search and AI answers now need separate visibility views.
The old report was built for monitoring positions. The modern one is built for diagnosing presence.
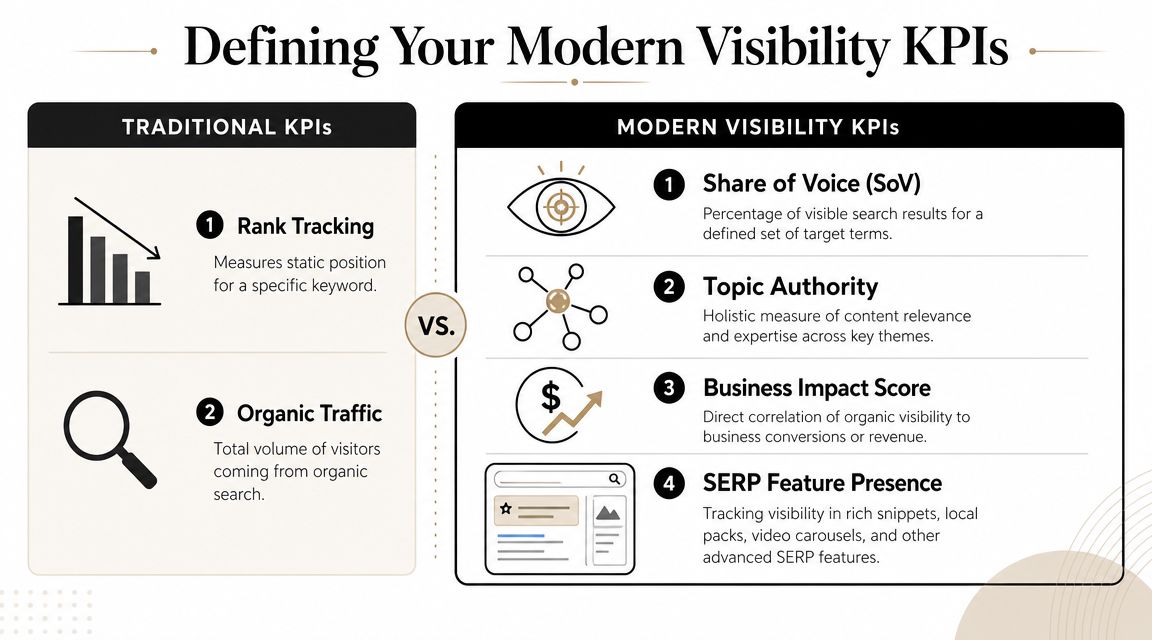
Defining Your Modern Visibility KPIs
A good keyword rankings and visibility report now behaves more like a business dashboard than an SEO worksheet. Modern reporting commonly includes keyword rankings, organic traffic, CTR, share of voice, AI mentions, answer share, and LLM citation tracking, reflecting a broader view of search presence rather than position alone, as described in this overview of the modern keyword rankings and visibility report.
What still belongs in the report
Don't overcorrect and throw out classic SEO metrics. They still matter because they tell you whether your owned assets are discoverable in conventional search environments.
Use the traditional layer to track:
Metric Category
Traditional KPI (SEO)
Modern KPI (SEO + AI)
Positioning
Exact keyword rank
Ranking distribution by band, plus answer presence by prompt set
Traffic
Organic sessions
Organic sessions plus AI-driven visits and citation-assisted discovery
Click behavior
CTR from search listings
CTR plus answer share and brand mention visibility
Competition
Competitor rank overlap
Share of voice across search and AI surfaces
Coverage
Indexed pages and ranking terms
Coverage by topic cluster, geography, intent, and model/channel
Search features
Basic SERP ownership
Featured snippets, local packs, AI mentions, and citation source share
The key shift is that rank tracking becomes a component, not the headline.
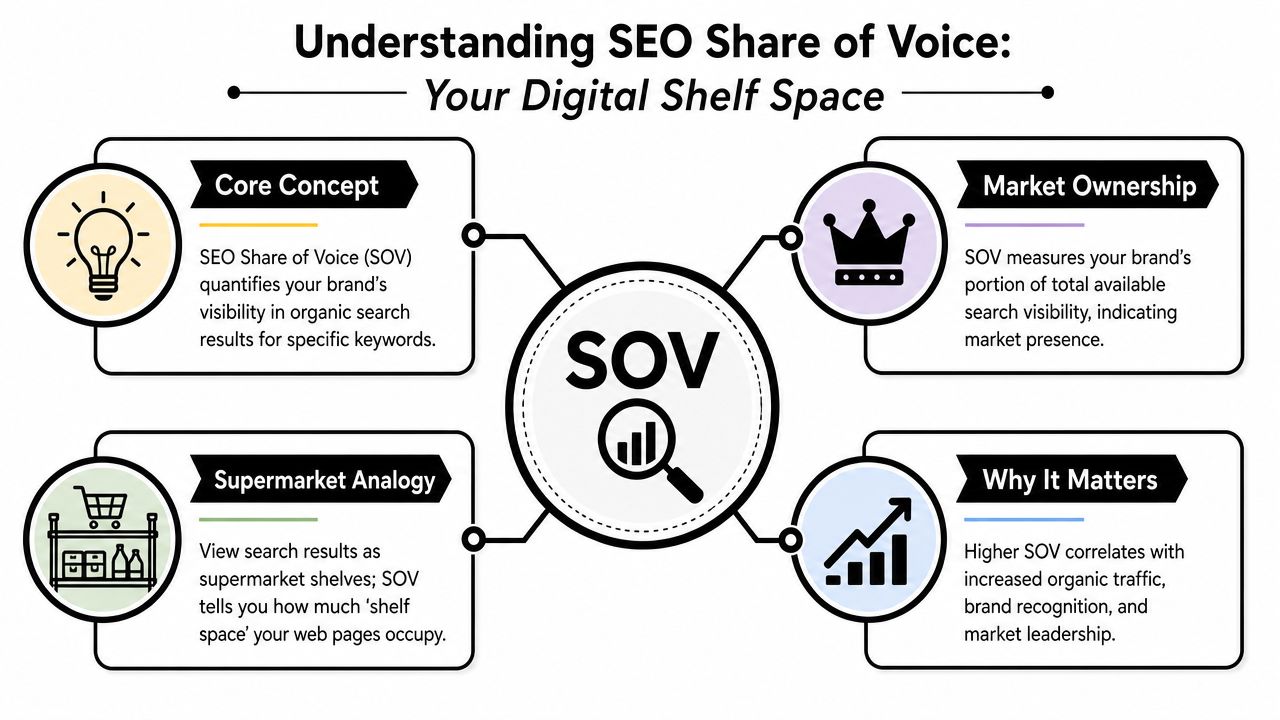
For share of voice, many teams still need a better operational definition. This explainer on SEO share of voice is useful because it grounds the metric in competitive search visibility rather than vanity ranking wins. That's the framing you want in the report.
What modern visibility adds
The report should also include metrics that reflect how people encounter brands in AI-mediated journeys. These aren't replacements for SEO metrics. They're the missing half.
A practical KPI set looks like this:
AI mentions: Whether your brand appears in responses for tracked prompts.
Answer share: How often your brand appears relative to competitors in the answer set.
Citation source share: Which domains or pages models cite when discussing your category.
Prompt visibility by intent: Whether you appear for discovery, comparison, evaluation, and purchase-oriented prompts.
Geographic visibility: Whether model answers vary by market or country.
Topic-cluster strength: Whether your brand appears consistently across a theme, not just a single prompt.
SERP feature presence: Whether you own rich surfaces that shape attention before the click.
A brand can have strong rankings and weak recommendation visibility. That's why modern KPI design has to separate discoverability from selection.
One more rule matters here. Keep these KPIs aligned to business use. A dashboard packed with prompt-level noise becomes unreadable fast. If a metric doesn't help someone decide what to create, fix, defend, or prioritize, it doesn't belong in the main report.
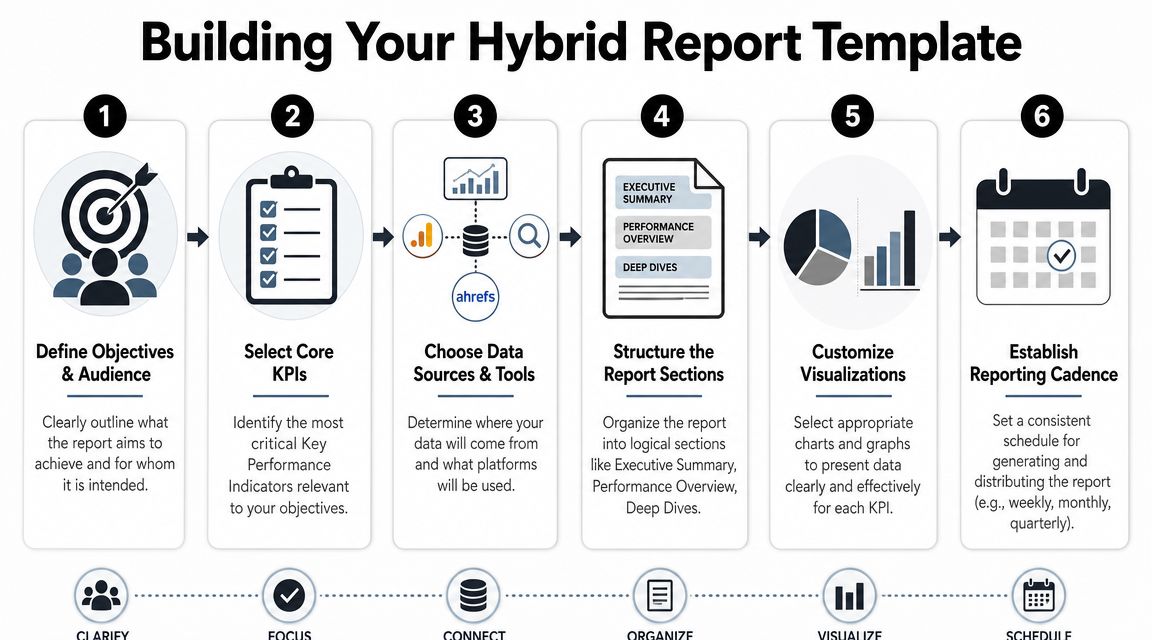
Building Your Hybrid Report Template
The fastest way to ruin a keyword rankings and visibility report is to dump every export into one dashboard. The report needs structure before it needs charts.
Start with a reporting spine
Build the report around a fixed set of dimensions. I recommend using these as the master keys across every data source:
Keyword or prompt set
Topic cluster
Intent stage
Geography
Channel or surface
Landing page or cited URL
Competitor set
Once those are stable, you can pull data from tools without turning the report into a patchwork. For traditional SEO, it is common to source from Google Search Console, Google Analytics 4, Semrush, Ahrefs, Similarweb, or Advanced Web Ranking. For AI visibility, use a platform that can monitor prompts, mentions, citations, and competitive response patterns. One option is AI-powered SEO workflows and search monitoring, which shows how teams are pairing classic optimization with AI visibility tracking.
Your first worksheet or data table should not be a dashboard. It should be a clean fact table with one row per tracked entity, whether that entity is a keyword, prompt, or grouped concept.
Unify the data model before you visualize it
Most reporting problems come from mismatched naming.
If one tool labels a theme “customer support software,” another calls it “help desk,” and a third tags it as “service platform,” your rollups will be unreliable. Create a controlled taxonomy and force every source into it.
Visibility types: Blue link, SERP feature, AI mention, AI citation
Workflow note: Teams that standardize taxonomy early spend less time explaining reporting discrepancies later.
This is also the right place to define competitor logic. Don't compare every brand against every other brand. Create peer groups. One competitor set for enterprise deals may be useless for a local search cluster or an AI recommendation prompt.
If you're using Google Sheets, build separate tabs for raw imports, taxonomy mapping, normalized data, and executive output. If you're using Looker Studio, Power BI, or another BI layer, keep the same logic. Raw data should remain untouched. Transformations belong in a repeatable layer.
Design dashboard views people will actually use
The final report should have modules, not one giant canvas.
A practical layout often includes:
Report Module
What it shows
Who uses it
Classic SEO Health
Ranking distribution, CTR, traffic trends, page-level winners and losses
Share of voice, topic ownership, geography gaps, overlap by intent
Leadership, strategy
Opportunity Queue
Pages to refresh, topics to expand, prompts to target, offsite sources to earn
Content, SEO, digital PR
The visual rule is simple. Every chart should help answer one of three questions:
Where did we lose ground?
Why did it happen?
What do we do next?
Avoid vanity visuals like blended average rank without segmentation. They look neat and explain almost nothing. Instead, show distribution charts, market comparison tables, intent-based filters, and page or citation drill-downs.
If you're building this for a multi-market team, include geography toggles from day one. If you're building it for a category with long buying cycles, include funnel-stage views. Those choices make the report operational instead of decorative.
Customizing the Report for Different Stakeholders
A master report is necessary. A single audience view is not.
What the executive team needs
An executive team rarely wants to inspect individual keyword movement. They want to know whether the brand is gaining or losing market presence in the areas that matter commercially.
Their version of the report should focus on:
Competitive share view: Are core categories becoming easier or harder to own?
Market-level movement: Which geographies are improving and which need intervention?
Business-risk summary: Where visibility is slipping in high-intent topics or strategic product lines.
Narrative shifts: Whether AI answers and search surfaces describe the brand accurately.
This view should fit on a small number of pages or dashboard tiles. The goal is decision support, not audit detail.
What content and SEO teams need
The working team needs the opposite. They need granularity.
For them, the best view usually includes prompt or keyword groups, landing pages tied to each group, ranking-band movement, citation patterns, and content gaps by topic cluster. The report should help them decide whether to refresh a page, publish a new asset, improve formatting for answer extraction, or build support content around a cluster.
A strong reference for simplifying these operational views is Keyword Kick's guide to client reports. It's written for client reporting, but the same discipline applies internally. Remove noise, keep decisions visible.
The right team view doesn't answer “How did SEO do?” It answers “What do we ship next?”
What PR and brand teams need
PR and brand teams need a narrative lens. They care less about average rank and more about how the company is represented.
Their cut of the report should isolate:
Brand mentions in AI responses
Citation sources shaping the narrative
Competitor comparison prompts
Topic areas where the brand is absent or misframed
Geographic differences in brand description
In this context, a unified report becomes more than SEO reporting. It starts functioning as a search intelligence layer across owned, earned, and AI-generated surfaces.
The master dashboard stays the same underneath. What changes is the lens, the filtering, and the summary language.
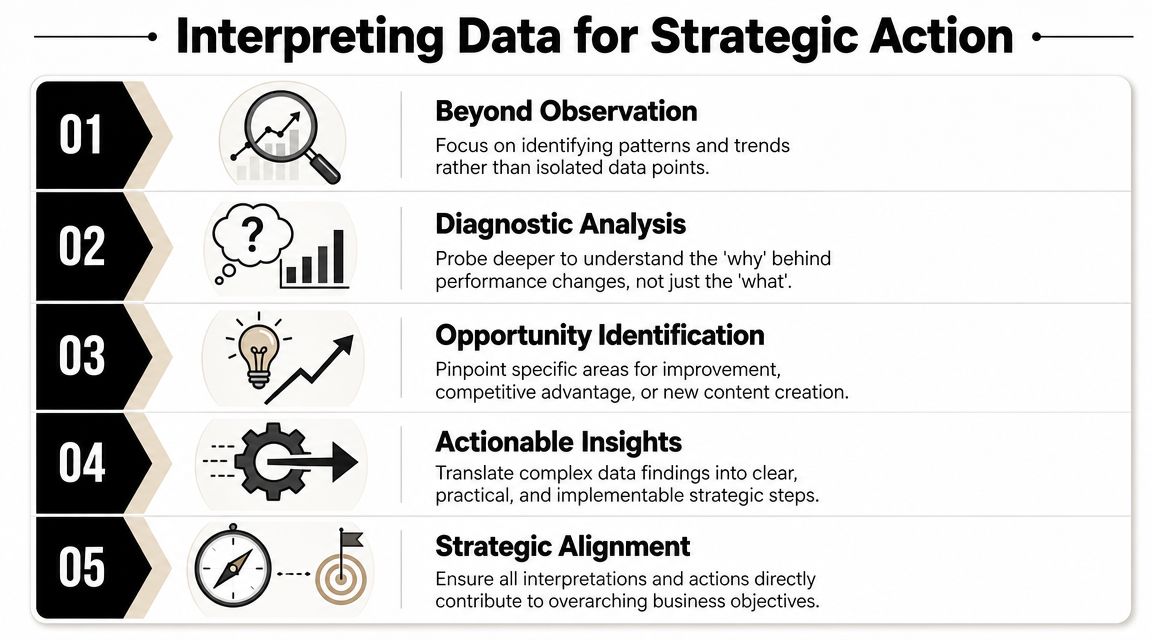
Interpreting the Data and Taking Action
A report only becomes useful when the team can tell the difference between noise and signal.
A keyword rankings and visibility report works best when it tracks performance over time instead of reacting to single-day movement. One industry guide recommends evaluating aggregated impressions and ranking data across at least 4 to 6 weeks, noting that daily volatility can reach 30% for some keywords, which makes short-term swings unreliable for decision-making in SEO reporting trend-based keyword visibility reporting.
Read patterns, not isolated movements
If a single keyword falls for a day, that's monitoring. If a ranking band weakens across a topic cluster over several weeks, that's a pattern.
The report should train your team to interpret grouped changes:
Stable traffic, weaker ranking distribution: You may be protected by branded demand or a few strong pages while broader discoverability erodes.
Flat rankings, weaker AI mentions: Your pages still rank, but competing sources are being selected more often in answer environments.
Improved visibility, weak engagement: You're appearing more often, but not for the right prompts, geographies, or stages of intent.
Strong informational growth, weak commercial presence: Content production is working, but revenue-oriented surfaces remain underdeveloped.
A good analyst doesn't ask whether one metric moved. They ask which metrics moved together.
Use signal combinations to choose the next move
Treat interpretation as a decision matrix. Here are practical examples.
If you see this
It usually suggests
Action to take
Keywords hold position but SERP feature visibility drops
You're still indexed well, but you're losing attention share
AI mentions rise but cited URLs are weak or off-message
Models are finding you, but not through the pages you want
Build or refresh canonical pages for the topic and tighten internal linking
Commercial prompts show competitor dominance
The market sees them as the safer choice in buying contexts
Audit their cited content, comparison pages, proof elements, and offsite validation
One geography underperforms while others stay steady
Local relevance or regional authority is weaker
Localize pages, review market-specific proof, align citations and local intent coverage
Topic cluster is visible but conversion pages are absent
You own education, not selection
Add solution, use-case, pricing, and comparison content tied to the cluster
Don't ask whether the report says performance is up or down. Ask what the report is telling your team to build, fix, defend, or stop doing.
This is the shift from reporting to intelligence. The report isn't the output. The next action is.
Automating and Distributing Your Report
Manual reporting breaks the moment you add multiple countries, prompt sets, competitors, and channels. The fix isn't just automation. It's disciplined cadence.
Set different cadences for different signals
Not every metric deserves the same schedule.
Brand-sensitive prompts, competitor mentions, and narrative issues should be monitored frequently because teams may need to respond quickly. Broader cluster-level visibility trends usually work better in a slower review cycle because they need context, not panic.
A sustainable operating model usually includes:
Frequent monitoring: Critical brand prompts, executive-risk topics, major competitor comparisons
For tooling, use APIs where possible, scheduled exports where necessary, and one destination for normalization. If you're evaluating platforms for the AI side, this roundup of AI search monitoring tools for tracking brand visibility is a practical starting point. Spotlight Group LLC is one option in this category. It tracks brand mentions, prompts, citations, competitors, and geo-specific results across major AI search platforms.
Distribute insight, not dashboards
Most dashboards are over-shared and under-read.
Executives need a summary. SEO teams need drill-down access. PR needs narrative alerts. Product marketing may only need visibility shifts for strategic categories. Set delivery based on use case, not habit.
Useful distribution patterns include:
Email summaries: Short takeaways with links to the live dashboard
Slack alerts: Triggered for major brand, competitor, or citation changes
Live BI access: Reserved for teams that actively work in the data
Monthly review decks: Built from the same reporting source, not recreated manually
There's also a lesson from adjacent monitoring disciplines. Teams that combine search reporting with broader market listening tend to spot context faster. For example, social listening with Instagram location data shows how location-aware signals can sharpen local market interpretation. The same principle applies here. Geography is often where visibility shifts become actionable first.
Frequently Asked Questions
How do you report on prompts that don't have clear search volume
Treat them as part of a topic cluster instead of forcing a false precision model.
AI discovery doesn't always map neatly to traditional keyword volume. The better method is to group prompts by job to be done, intent, and business priority, then track whether your brand appears consistently across the cluster. That gives you directional intelligence without pretending every prompt behaves like a classic search term.
What counts as a good visibility score
There isn't a universal number that matters across every category.
A useful benchmark is relative. Compare your visibility against direct competitors in the prompts, topics, and geographies that affect pipeline. Then track internal improvement over time. A score is only meaningful if it helps you judge whether your presence is strengthening in the right places.
Can you build this manually
Yes, but only to a point.
You can combine Google Search Console, GA4, rank tracking exports, spreadsheets, and periodic prompt testing. That works for a small footprint. It usually breaks when you add multi-market monitoring, recurring competitor comparison, citation analysis, and stakeholder-specific views.
Manual spot checks also create consistency problems. One person asks a slightly different prompt, from a different location, on a different day, and the result looks like a strategic change when it isn't. That's why repeatable monitoring matters more than clever screenshots.
Should AI visibility replace traditional SEO reporting
No. It should sit beside it.
The strongest reporting model is hybrid. Traditional SEO still tells you whether your pages are discoverable and competitive in search results. AI visibility tells you whether your brand is being selected, cited, and described in answer environments. You need both views to understand the full path from discovery to decision.
What's the biggest mistake teams make with this report
They overload it with metrics and underinvest in diagnosis.
If the dashboard can't tell a team where visibility changed, why it likely changed, and what action to take next, it's just a prettier spreadsheet.
Spotlight Group LLC helps teams monitor brand visibility across AI search and conversational platforms, including mentions, prompts, citation sources, competitive comparisons, and geo-specific results. If you're updating your keyword rankings and visibility report for AI search, Spotlight Group LLC is worth evaluating alongside your existing SEO and BI stack.
Most advice on how to get SEO clients is built around one assumption: you need more leads. More cold emails. More LinkedIn messages. More networking. More audits.
That usually isn't the actual problem.
The hard part isn't finding businesses that could use SEO. There are plenty of those. The hard part is convincing the right businesses that your work will produce business outcomes they care about, and doing it through a process you can repeat without burning out. If your pitch still centers on rankings, traffic, and generic “visibility,” you're forcing prospects to trust a future they can't clearly value.
A lot of useful tactical advice exists, including these best ways to attract SEO clients. But tactics only work when they sit inside a system. That system needs positioning, qualification, proof, and a way to move a skeptical buyer from interest to confidence. Agencies that want a sharper operating model can also study how other firms structure growth and delivery on agency strategy examples.
The agencies that win consistently don't just generate attention. They reduce uncertainty. They show a prospect what success looks like in booked calls, qualified opportunities, and revenue influence. Then they back that up with a sales process that qualifies hard, proposes clearly, and reports against outcomes.
A weak client acquisition process creates a bad habit. When deals don't close, agencies assume the fix is more volume. So they send more messages to worse-fit prospects and make the trust problem even worse.
That cycle gets expensive fast. You spend time prospecting, writing, following up, and jumping on calls with companies that were never likely to buy a serious SEO engagement in the first place. The answer isn't louder outreach. It's tighter selection and stronger proof.
Practical rule: If your sales process begins with “we do SEO,” you're already behind. Buyers care about the business problem first.
A dependable system has three parts:
A clear target market that lets you recognize strong-fit prospects quickly.
A value proposition tied to business outcomes instead of channel activity.
A conversion process that qualifies, diagnoses, and proposes in the same direction.
Most agencies fail because they only build the third part. They script outreach before they define who they're for. They promise deliverables before they know what the client values. They chase leads before they know how to prove impact.
The result is familiar. Prospects ask about price early, compare you to cheaper vendors, and treat SEO like a commodity. That's not a lead shortage. That's a positioning failure.
Define Your Value and Your Ideal Client
Generalist agencies usually think broad positioning gives them more opportunities. In practice, it makes them harder to buy. A buyer wants to know whether you understand their business model, their sales cycle, and the commercial stakes behind their search presence.
The strongest position is simple: serve a specific type of client, solve a recurring problem, and explain the result in terms that matter to management.
Pick a niche with operational advantages
A niche isn't just a market category. It's an efficiency decision.
When you specialize, your sales calls get better because you've heard the same objections before. Your audits get faster because the site patterns repeat. Your onboarding improves because you already know the stakeholders, approval loops, and common blockers. You stop reinventing your process for every account.
Good niches often share a few traits:
They have clear commercial intent. Think local service businesses, multi-location brands, B2B companies with sales teams, or e-commerce brands where organic traffic supports revenue directly.
They have recurring SEO problems. Thin service pages, weak internal linking, messy location architecture, low-content category pages, or poor non-brand capture.
They can measure downstream outcomes. If the client already tracks leads, pipeline, or booked calls, your case gets easier.
If you need help identifying qualified potential customers, use that lens before you ever build a prospect list. “Needs SEO” is not qualification. “Has the economics, urgency, and reporting maturity to value SEO properly” is closer.
Another useful filter is strategic relevance. If you're working with brands that also care about how they appear in emerging search environments, this broader view on agency strategies for AI search visibility across multiple client brands is worth studying because it sharpens how you think about positioning beyond classic rankings.
Sell an outcome, not a channel
Most agencies still describe themselves with channel language. Technical SEO. Content SEO. Link building. Local SEO. That's accurate, but it isn't persuasive.
The better framing is to connect your work to decision-stage outcomes. That's the buyer question most agencies dodge. As noted by Marketers Center in its guide on where to find local SEO clients, clients do not just want leads; they want proof that SEO can be measured against revenue and pipeline. Agencies that position around booked calls, qualified opportunities, and revenue influence stand out against firms promising traffic growth alone.
That changes how you speak:
Instead of “we improve rankings,” say you improve visibility on pages that support pipeline creation.
Instead of “we publish content,” say you build assets that capture demand from high-intent searches.
Instead of “we track traffic,” say you measure whether organic sessions contribute to qualified actions.
Buyers don't reject SEO because they hate SEO. They reject vague commercial logic.
A strong value proposition usually has four parts. Who you help, what problem you solve, what business outcome you target, and why your method reduces risk. If any of those parts are fuzzy, your outreach gets ignored and your proposals feel generic.
Build a simple forecast before the proposal
You don't need an elaborate spreadsheet to make SEO easier to buy. You need a believable model.
That model should translate search opportunity into business language. Start with the pages or keyword clusters closest to buying intent. Estimate what actions matter on those pages, such as form submissions, demo requests, booked consultations, or product page visits that lead to purchase. Then discuss how improved visibility could influence those actions over time.
Keep it directional. Don't pretend precision you don't have.
A useful forecast conversation sounds like this:
Map the buying journey. Which searches indicate early research, active comparison, or decision-stage intent?
Identify conversion points. What counts as a qualified action on the site?
Connect SEO work to those actions. Which pages, templates, or topics can realistically influence them?
State assumptions openly. Tell the prospect what must happen operationally for the model to hold.
This is one of the biggest differences between agencies that win premium work and agencies that get pushed into price shopping. Premium buyers don't just want activity. They want an argument they can defend internally.
Build a Diversified Lead Generation Engine
Agencies get into trouble when acquisition depends on one channel and one founder's energy. A healthier setup spreads risk across channels with different payback periods, control levels, and trust mechanics. That mix gives you steadier deal flow and better-fit opportunities.
Compare channels by speed, control, and fit
Channel choice should start with one question: which mix helps you prove commercial value fastest to the right buyer?
Channel
Time Investment
Monetary Cost
Lead Quality
Best For
Content marketing
High upfront
Moderate
High when niche-specific
Agencies building long-term authority
Outbound prospecting
Ongoing
Low to moderate
Strong if qualification is tight
Agencies that need pipeline control
Referrals
Low to moderate
Low
Usually high
Firms with happy clients and strong relationships
Partnerships
Moderate
Low to moderate
High when incentives align
Specialists serving complementary providers
Paid ads
Moderate
High
Mixed without sharp positioning
Agencies with clear offers and landing pages
Networking and events
Moderate
Moderate
Mixed but trust-rich
Founders who sell well in conversation
The trade-off is simple. Outbound gives control. Content compounds. Referrals close faster but are hard to forecast. Partnerships can produce excellent fit, but only if both sides serve the same buyer and define handoff rules clearly. Paid ads can work, though they expose weak positioning fast.
If you want a broader strategic take on building a scalable lead generation engine for agencies, that framework pairs well with this one. The goal is to choose channels that match your stage, niche, and sales capacity, then measure them by qualified conversations and revenue potential, not raw lead volume.
Use outbound like a qualification system
Outbound works when the list is doing half the selling.
Prospects should already fit your niche, show signs of demand capture problems, and have a business model where better search visibility could plausibly increase revenue. That last part matters. A site with weak rankings is not automatically a good client. Some companies lack sales follow-up, offer clarity, or conversion paths. Sending audits to those accounts creates meetings that go nowhere.
Use filters that reflect commercial fit:
Revenue logic: Is there a clear path from search intent to pipeline, booked calls, or purchases?
Offer clarity: Can a buyer understand what the company sells within a few seconds?
Search opportunity: Are there obvious gaps on service, category, comparison, or location pages?
Execution readiness: Does the business appear able to publish, approve, and act on recommendations?
Account value: Would a win here produce enough revenue and proof to justify the sales effort?
A smaller list with better fit beats a giant spreadsheet full of businesses that will never buy premium SEO.
Create inbound assets that pre-sell your expertise
Inbound assets should answer the buyer's real question before the first call. How will this make me money?
That means creating material that connects SEO work to business outcomes. Publish teardown posts on pages that influence high-intent searches. Build templates that help prospects estimate opportunity. Offer short calculators, page scoring sheets, or forecasting frameworks they can use internally. If you produce content around AI search and conversational visibility, this roundup of tools for AI search content writing and conversational search optimization is a useful reference point for asset ideas.
Useful inbound assets include:
Niche teardown posts that show recurring revenue leaks in one vertical
Mini-tools or templates such as content brief formats, page scoring sheets, or simple forecasting models
Webinars and workshops for partner audiences that already serve your target accounts
Case-based opinion pieces that explain what changed, what metric moved, and why the result mattered commercially
Good inbound content does not try to impress everyone. It helps the right buyer self-qualify.
A diversified engine gets stronger when channels support each other. Content gives outbound more credibility. Strong delivery creates referrals with context, not vague praise. Partnerships shorten trust-building because someone else has already validated your process. That is how agencies stop chasing random leads and start building a repeatable client acquisition system.
Mastering Outreach and the Diagnostic Call
A prospect list doesn't create revenue. Conversations do.
Most outreach fails because it asks for commitment before earning attention. The prospect doesn't know you, doesn't trust your diagnosis, and doesn't see enough commercial relevance to reply. The fix isn't a clever subject line. It's a message based on a real observation tied to a real business issue.
Personalize after qualification, not before
Many agencies waste time customizing outreach for accounts they haven't earned the right to fully pursue. That's backwards.
SEO Inc outlines a stronger acquisition path in its article on customer acquisition through SEO. The workflow starts with defining the ideal customer, then using CRM, analytics, and marketing automation data to score prospects by fit and intent, and only after that personalizing outreach or landing page experiences. It also stresses measuring bottom-of-funnel outcomes such as MQL-to-SQL conversion and cost per acquired customer instead of top-of-funnel clicks.
That sequence is practical because it protects your time. Personalization is expensive. Qualification should come first.
A good first-touch message usually does three things:
Shows specific awareness. Mention an issue you noticed, not a canned compliment.
Connects that issue to a business consequence. Don't stop at “your title tags are weak.”
Offers a low-friction next step. A short call, a short teardown, or a quick screen share.
Bad outreach sounds like a freelancer asking for work. Good outreach sounds like a consultant noticing a solvable problem.
Run discovery like a diagnosis
The first call shouldn't feel like a presentation. It should feel like an investigation.
Your job is to uncover four things. The business objective, the commercial cost of the current gap, the internal buying process, and whether the account is winnable. If you miss any of those, your proposal will be weaker than it looks.
Use questions that force specificity:
Business context: What growth targets matter most this year?
Lead quality: Which conversions count as qualified?
Sales reality: What happens after a lead comes in?
Internal ownership: Who signs off, and who will manage implementation?
Past frustration: What has already been tried, and where did it fail?
Then listen for buying signals. A serious buyer talks about pipeline, sales capacity, margins, location expansion, category growth, or pressure from leadership. A weak-fit buyer stays at the level of “we just want more traffic.”
Field note: If a prospect can't define what a good lead looks like, don't rush to write a proposal. Slow the process down and qualify harder.
The strongest calls also include gentle challenge. If a prospect wants national visibility with weak service pages, slow approval cycles, and no content owner, say so. Respect goes up when you diagnose candidly.
Move from interest to proposal
A proposal should feel like a continuation of the call, not a surprise document.
Before you write it, confirm the core facts back to the client in plain language. The business objective, the current bottlenecks, the pages or categories with the clearest opportunity, the resources required on their side, and the reporting framework you'll use. That recap alone filters out many shaky opportunities because it forces alignment before paperwork.
A simple transition works well:
Restate the problem in commercial terms.
Name the priority workstreams without overwhelming detail.
Tie reporting to business actions the client already values.
Set expectations on what must happen operationally for the engagement to work.
That approach changes the mood of the sale. You're no longer trying to convince them SEO is valuable in theory. You're showing how your process addresses the specific gap they acknowledged.
Pricing, Packaging, and Closing the Deal
Pricing gets messy when the service is vague. It gets cleaner when the client understands the problem, the scope, and the business importance of solving it.
Most agencies struggle here because they mix two different conversations. One is about deliverables. The other is about value. If you skip the value conversation, the prospect compares your fee to a cheaper SEO vendor with no context.
Choose the pricing model that matches the problem
No pricing model is universally best. The right one depends on uncertainty, implementation complexity, and the client's buying preference.
Monthly retainers work best when the client needs sustained execution across technical work, content, strategy, reporting, and iteration. They create stability for both sides, but only if the scope is clear enough that the client doesn't feel trapped in an endless to-do list.
Project-based pricing fits defined engagements. Think migrations, audits, content architecture overhauls, local page expansions, or a focused remediation plan. This model is easier to sell when the client wants a contained decision before considering a longer relationship.
Performance-based structures sound attractive, but they often create alignment problems unless the tracking, attribution, lead quality rules, and implementation control are very clear. If you don't control enough of the funnel, performance pricing can become an argument about factors outside your hands.
A practical rule is simple:
Use retainers for ongoing growth systems.
Use projects for bounded transformation work.
Use performance components only when both parties agree on how outcomes are defined and measured.
Keep proposals short and decision-focused
Long proposals often signal uncertainty, not sophistication.
The strongest proposal many agencies can send is one page plus a short appendix if needed. Keep the main document focused on the decision. The client doesn't need a textbook on SEO. They need confidence that you understand the problem and have a credible plan.
A sharp proposal includes:
Objective: What business outcome the engagement supports.
Current constraints: The few issues blocking progress.
Scope: What you will do first.
Timeline: The sequence of work and major milestones.
Investment: The fee, payment structure, and term.
Dependencies: What the client must provide for success.
This format also helps close faster because it limits drift. A bloated deck invites side debates about every tactic. A concise proposal keeps the conversation where it belongs.
Handle objections by returning to value
Most objections aren't really about price. They're about confidence.
When a prospect says, “It's expensive,” they're usually saying one of three things. They don't yet see the business value. They don't trust the plan. Or they aren't sure your firm is the safest choice.
Respond by going back to the diagnosis:
If they question cost, reconnect the fee to the opportunity or problem cost discussed on the call.
If they question ROI, return to the assumptions behind the forecast and the reporting model.
If they need more certainty, narrow the initial scope and define a clear first phase.
Don't become defensive. Don't start discounting immediately. And don't pile on extra deliverables just to justify the fee. That's how margins collapse and expectations explode.
A close is usually strongest when it sounds calm. You understood the issue, you've scoped a response, and you've explained how progress will be judged. That gives a serious buyer enough confidence to move.
Onboarding, Retaining, and Turning Clients into Raving Fans
The sale isn't complete when the contract is signed. It's complete when the client feels they made a smart decision.
That feeling gets built early. The first stretch of the relationship shapes retention, referrals, review quality, and the odds that the client will expand scope later. Agencies that retain well don't rely on charm. They operationalize clarity.
Win the first ninety days
The first phase should remove confusion fast.
Start with a kickoff that confirms goals, stakeholders, communication rules, approval paths, and what success will be judged against. Then move quickly into actions that create visible momentum. That doesn't mean chasing vanity wins. It means solving issues the client can understand and explaining why those actions matter.
Strong onboarding usually includes:
A shared success definition tied to the actions or outcomes the client values.
A documented roadmap with priorities, owners, and review points.
A clear reporting cadence so nobody wonders what happens next.
Early education on what SEO can influence directly and what requires support from other teams.
Clients stay when they can see what you're doing, why you're doing it, and how it connects to their business.
Report in the language clients use internally
Retention improves when reporting matches how the client makes decisions.
A marketing manager may care about lead quality and conversion paths. A founder may care about sales conversations and revenue contribution. An operations lead may care about location-level visibility or implementation dependencies. If your report is full of jargon and detached metrics, you force the client to translate your work for everyone else.
Good reporting does three things well:
Explains progress on the work itself.
Connects work to meaningful actions such as inquiries, demos, or qualified opportunities.
Flags risks and dependencies before they become excuses.
Quarterly reviews matter here. They create space to revisit objectives, reset priorities, and show the client that your thinking goes beyond task execution.
Turn retention into acquisition
The easiest new client to win is often connected to a current one.
When service quality is high, client acquisition gets easier in ways most agencies underestimate. Happy clients give testimonials. They introduce peers. They become proof that your process works in a real operating environment. Even when a formal case study isn't available, a client who confidently explains your value to someone else can shortcut months of trust-building.
That only happens when the delivery side supports the sales promise. If you sell revenue impact and then report only rankings, referrals will be weak. If you diagnose carefully, set expectations clearly, and communicate with discipline, retention starts feeding acquisition.
A mature agency doesn't treat sales, delivery, and retention as separate departments with separate logic. It treats them as one system. That's how you stop chasing random leads and start building a client base that compounds.
If your team wants to prove visibility in AI search the same way strong agencies prove SEO impact in traditional search, Spotlight Group LLC is built for that job. It helps brands monitor where leading AI models mention them, see the prompts customers use, understand citation sources, and connect those insights to action through GEO-focused content, offsite outreach, and reporting tied to traffic outcomes.
You're probably in one of two places right now. Either you're staring at a half-finished YouTube script and thinking, “AI should make this easier than this,” or you've tried a few AI tools already and ended up with content that sounds polished but empty.
That gap is where most creators get stuck. An AI content generator for YouTube can absolutely speed up research, scripting, titles, thumbnails, voiceovers, and first-pass edits. But speed by itself doesn't build a channel people trust, watch, and come back to. The channels that make the most of AI use it as a production system, not a vending machine.
Beyond the Blank Page An AI-Powered YouTube Strategy
Creative burnout on YouTube rarely looks dramatic. It looks like opening YouTube Studio, checking what underperformed, feeling the pressure to publish again, and realizing you still need a topic, a script, a title, a thumbnail angle, and enough energy to make the whole thing worth watching.
That's why AI has become practical infrastructure for creators, not a novelty. A 2024 ACM study on generative AI in YouTube creator workflows found that 58.21% of sampled videos used Gen-AI for content generation, making generation the leading use case over simpler tasks like editing or analytics. In the same study, LLMs accounted for 41.79% of the tools observed, and 35.82% of the videos used Gen-AI for suggesting ideas or topics. That tells you something important. Creators aren't only using AI after the content exists. They're using it upstream, where videos are won or lost.
This visual captures the shift from scattered effort to a repeatable system.
What an AI workflow should actually do
A useful AI stack for YouTube does four jobs well:
Find angles worth making: not generic “10 video ideas,” but specific questions, objections, and gaps your niche hasn't covered well.
Turn a topic into assets fast: script draft, title options, thumbnail concepts, description, chapters, and repurposed short-form cuts.
Reduce low-value production work: first-pass voiceover, rough B-roll, scene grouping, silence removal, and draft edits.
Create a feedback loop: analytics tell you what failed, and your next prompts get better.
Practical rule: If AI only saves time but makes your videos more interchangeable, it's hurting the channel.
A lot of tutorials still frame AI around faceless quantity. That's too shallow. The better model is controlled assistance. You keep the positioning, judgment, and final polish. AI handles the repetition, the first draft, and the format work. If you want a complementary walkthrough focused on actual video generation workflows, ClipCreator.ai's guide on AI video is a useful reference because it connects creation speed with the production choices that still need human review.
The channel-level mindset
The right question isn't “Can AI make a YouTube video?” It can. The better question is whether your workflow produces videos that still feel distinct after AI touches every stage.
That's the standard that matters if you want monetizable, durable growth. Everything that follows works from that assumption: AI should reduce friction, not flatten your voice.
Phase 1 Strategic Ideation and Topic Validation
Most creators waste AI at the exact point where it could be most valuable. They open ChatGPT or Claude, type “give me 20 YouTube ideas,” and get back a list that could fit any channel in the niche.
That's not strategy. It's autocomplete.
Stop asking for random ideas
The strongest use of an AI content generator for YouTube is narrowing the field before production starts. You want AI to help answer questions like these:
What has already been covered to death?
Which subtopic gets attention but weak explanations?
What beginner question keeps appearing in comments and forums?
Which angle can this channel credibly own?
There's also a quality reason to work this way. The Luma discussion around AI faceless video workflows highlights a core risk: AI-generated YouTube content can become unmonetizable or low-trust if it turns repetitive, which puts pressure on creators to compete on differentiation and retention, not just output speed. If your topic selection is generic, the rest of the workflow will be generic too.
Prompts that surface better topics
Use AI like an analyst, not an idea slot machine. Feed it context, examples, and constraints.
Here are prompt patterns that produce stronger topics:
Competitor gap analysis Prompt: “Act as a YouTube strategist for a channel about [niche]. Analyze the top videos and common angles for the topic [keyword]. Identify three underserved subtopics, two audience objections that aren't answered well, and one angle that would feel fresh to a viewer who has already watched the standard videos.”
Audience intent mapping Prompt: “For a YouTube audience interested in [topic], group likely viewers into beginner, intermediate, and buyer-intent segments. For each segment, list the questions they're most likely to click, watch, and save.”
Format validation Prompt: “Compare whether this topic is better suited to a Short, a standard tutorial, a case breakdown, or a commentary format. Explain which version gives the best chance of holding attention.”
Good ideation prompts ask AI to compare, prioritize, and critique. Weak prompts only ask it to generate.
A useful filter at this stage is asking whether the idea creates a clear promise. If you can't state the viewer outcome in one sentence, the topic usually isn't sharp enough yet.
A simple validation checklist
Before a topic moves into scripting, run it through a manual review:
Specific viewer problem: Can you name the exact pain point?
Clear payoff: Will the viewer know what they gain by the end?
Fresh framing: Is there a stronger angle than the obvious version?
Proof path: Can you support the script with examples, workflow detail, or direct experience?
Channel fit: Does this reinforce what the channel should be known for?
The strongest topics usually aren't the biggest ones. They're the ones with a sharp audience match and a specific promise that weaker channels gloss over.
Phase 2 Crafting High-Retention Scripts and Assets
Once the topic is validated, most of the value comes from asset cohesion. The script, title, thumbnail concept, and description should all describe the same promise from slightly different angles. When these pieces drift apart, the video gets clicks without retention, or retention without clicks.
That's where a disciplined prompt structure matters more than the model itself.
The script prompt should be narrow
A common mistake is dumping everything into one giant prompt. You add your brand voice, target audience, keywords, references, tone notes, visual direction, monetization goals, sponsor read, CTA, and five examples. Then the output comes back muddy.
That failure mode isn't surprising. InVideo's tutorial on AI video generation recommends being “very direct” with the initial prompt, including only the essential project details, then using the tool's follow-up questions to lock in settings like audience, duration, and media choices during refinement in the next step of the workflow, as shown in InVideo's guidance on direct prompting.
Start with the core assignment. Add complexity after the first useful draft appears.
A better initial script prompt looks like this:
Write a YouTube script for a video about [topic]. Audience: [who this is for]. Outcome: [what the viewer should understand or be able to do]. Format: hook, problem, explanation, examples, mistakes, closing CTA. Tone: clear, practical, not hypey. Keep the language concrete and avoid filler.
That's enough to get a workable skeleton. After that, refine in passes.
Edit in layers, not all at once
Use separate prompts for separate jobs:
Hook pass: “Give me 5 opening hooks for this script. Each should create curiosity without sounding clickbait.”
Retention pass: “Mark any paragraph where the pacing drops or the point gets repetitive. Rewrite for tighter flow.”
Voice pass: “Remove generic AI phrasing. Make this sound like an experienced YouTube strategist who values clarity over hype.”
Proof pass: “Flag any claim that needs evidence, qualification, or softer wording.”
This is also the point where the best teams pair writing tools with process tools. If you're evaluating your stack for search-driven content as well as scripts, this guide to the best tools for writing content optimized for AI search in 2026 can help you decide where a general LLM is enough and where a workflow layer is useful.
AI Prompt Templates for YouTube Assets
Asset Type
Example Prompt
Script draft
“Write a YouTube script about [topic] for [audience]. Use this structure: hook, problem, three key points, common mistake, practical takeaway, CTA. Keep the tone direct and useful.”
Title options
“Generate 10 YouTube title options for a video about [topic]. Prioritize clarity, curiosity, and a strong viewer outcome. Avoid generic phrasing.”
Thumbnail concepts
“Describe 6 thumbnail concepts for this video. For each, include the main visual subject, facial expression if relevant, short on-image text, and the core emotion or curiosity trigger.”
Description
“Write a YouTube description for this video using a strong first two lines, a concise summary, relevant keywords naturally, and a CTA to watch the next related video.”
Chapters
“Create chapter timestamps from this script using concise labels that match what viewers are trying to learn.”
Shorts repurpose
“Turn this long-form script into 3 YouTube Shorts concepts. Each should have a fast hook, one core point, and a clean ending line.”
Asset checks before production
Before you record or generate anything, review the package as a unit.
Title and thumbnail alignment: They should promise the same payoff, not two different stories.
Script opening match: The first lines should cash the promise immediately.
Description support: It should reinforce the topic, not stuff keywords.
Thumbnail feasibility: If your designer or image tool can't create it cleanly, the idea isn't production-ready.
A good AI workflow doesn't stop at “draft complete.” It hands production a package that already knows what the video is trying to do.
Phase 3 AI-Assisted Production and Editing
The biggest myth in this category is the one-click channel. It's easy to generate a script, a voiceover, a set of visuals, and a rough cut. It's much harder to make those pieces feel intentional once they sit next to each other on a timeline.
That difference is where channels either start looking polished or disposable.
Where AI helps most in production
AI is strongest in production when the task is repetitive, modular, or easy to evaluate quickly.
Use it for:
Voiceover drafts: Generate a first-pass read for explainer videos, faceless segments, or scratch audio used to test pacing before a final narration.
B-roll generation: Create supporting visuals for abstract concepts, transitions, or scenes that would otherwise require stock hunting.
Rough editing: Let AI tools detect pauses, group similar clips, remove silence, transcribe dialogue, and assemble a draft timeline.
Subtitle generation: Fast captioning is table stakes now, and AI usually gets you close enough to finish with a quick review.
This can cut a lot of friction from the middle of the process. It's especially useful when you need to test whether a concept works before committing to a full edit.
Where human judgment still decides quality
The last mile is still human. That includes pace, timing, emphasis, visual logic, and emotional tone.
Here's the hidden work AI can't do reliably without supervision:
Choosing what to linger on AI can cut dead air. It can't always tell when a pause adds tension or when an extra beat helps a point land.
Protecting brand consistency A channel voice is more than wording. It includes music taste, motion style, framing, humor level, and how aggressive or calm the edit feels.
Fixing visual emptiness Many AI-generated clips look technically usable but emotionally flat. If every scene has the same texture, the video starts feeling synthetic even when viewers can't explain why.
The fastest edit isn't the best edit. The best edit is the one where the viewer never notices the workflow behind it.
The practical way to run AI in production is to let it generate options, not final answers. Build a shortlist of voice takes, visual styles, and rough cuts. Then review them against the script's real job: hold attention and make the promise feel earned.
If you skip that stage, the channel starts to look like every other AI-assisted channel using the same templates, the same stock cadence, and the same empty confidence.
Phase 4 Optimizing for YouTube and AI Search
A video can be strong and still get packaged poorly. This happens all the time with AI-assisted workflows because creators spend their prompt energy on the script, then rush the title and metadata.
That's backward. Packaging is where the video earns the right to be watched.
Build titles with structured inputs
Hootsuite's title workflow is a useful model because it forces specificity. Their AI YouTube title generator uses four inputs in sequence: language, channel or video category, a short video description, and relevant search keywords, then generates up to five title options per run according to Hootsuite's YouTube title generator workflow. That structure matters because it reduces ambiguity and helps the model match audience language with search intent.
If you're writing title prompts manually, use the same framework:
Language
Category
Short description
Primary keywords
Then ask for variations across styles:
outcome-driven
curiosity-led
beginner-friendly
authority-based
contrarian
A strong title prompt looks like this:
Generate 8 YouTube titles in English. Category: YouTube growth strategy. Video description: A practical workflow for using AI to research, script, produce, and optimize YouTube videos without making them generic. Keywords: AI content generator for YouTube, YouTube AI workflow, AI YouTube script. Create 2 direct titles, 2 curiosity titles, 2 search-focused titles, and 2 titles that emphasize monetizable quality.
Extend one video into a search package
Don't stop at the title. A mature AI workflow turns one upload into multiple discoverability assets.
Use AI to generate:
Description variants: one concise version for clarity, one more keyword-aware version for testing
Chapter labels: clear timestamps improve navigation and help viewers find the exact segment they want
Pinned comment drafts: summarize the core takeaway and point viewers to the next related video
Short-form derivatives: turn one long-form argument into multiple Shorts hooks
Off-platform summaries: repurpose the script into a blog summary, LinkedIn post, or X thread
Better optimization starts with better inputs, not more keywords.
If you're thinking beyond YouTube search and want your videos and supporting content to be more visible in AI-driven discovery, this guide on how to create YouTube content that gets cited by AI chatbots is a smart companion to your packaging workflow.
The best packaging doesn't sound engineered. It sounds obvious in hindsight. That's usually the sign that the title, description, and chapters all came from the same clear understanding of the core purpose of the video.
Phase 5 Measuring Performance and Refining Your Prompts
Most AI workflows break because creators treat prompting as a creative act instead of an operational asset. They write a prompt, get a result, publish a video, and move on. That leaves no system for learning.
What improves channels isn't AI by itself. It's the loop between prompts, outputs, and performance.
This summary visual is a good way to think about that loop.
Read the signals that matter
You don't need more AI at this stage. You need better diagnosis.
Start with the clearest signals in YouTube Analytics:
Click-through rate: tells you whether the packaging earned attention
Audience retention graph: shows where the script and edit lost people
Traffic sources: helps separate a topic problem from a distribution problem
Comments and qualitative feedback: often reveal trust issues faster than any dashboard
Then map those outcomes back to the prompt that shaped the asset.
If retention drops early, review the script prompt and opening structure. If click-through is weak, inspect the title and thumbnail prompts. If viewers say the video feels vague, your ideation prompt probably approved a topic that was too broad.
Treat prompts like production assets
Keep a prompt library the same way you'd keep thumbnail templates or editing presets. Label prompts by function and outcome.
For example:
Prompt Type
What to review after publishing
Topic validation prompt
Did the video attract the right audience?
Script hook prompt
Did viewers stay through the opening?
Title prompt
Did the packaging create the right expectation?
Shorts repurpose prompt
Did the derived clips stand alone cleanly?
There's also a cost layer most creators ignore. The analysis of AI YouTube production economics points to a real issue: some tools charge per second of generation, which means AI doesn't always reduce cost. Sometimes it just shifts cost from labor into subscriptions, retries, and cleanup editing. That matters when an AI content generator for YouTube starts expanding from “helpful assistant” into a chain of paid tools that each add one more draft, one more export, and one more revision step.
Watch for this pattern: the workflow feels faster, but the publishable version still depends on heavy correction. That's not automation. That's cost relocation.
The teams that get lasting value from AI usually make three adjustments:
They cut tools that only produce novelty. If an output still needs major repair every time, it's not saving much.
They refine prompts after every meaningful win or miss. A strong prompt gets versioned, not forgotten.
They compare workflow by format. Shorts, long-form explainers, and image-to-video pieces often behave differently in both effort and quality.
That's the difference between using AI occasionally and running an AI-assisted content operation that gets sharper over time.
If your team wants to go beyond YouTube workflow tips and measure how your brand shows up across AI-driven discovery, Spotlight Group LLC is built for that job. Spotlight helps brands track where leading AI platforms mention them, which prompts trigger those mentions, which sources get cited, and how visibility changes over time so content, SEO, and brand teams can act on something measurable instead of guessing.
Google still treats ecommerce as a crawling and indexing challenge, not just a copywriting challenge. Its own Search Central ecommerce guidance puts structured data, canonicalization, index control, and complete product detail pages at the center of visibility. That's the surprising part for many teams chasing AI search: before ChatGPT, Gemini, or Perplexity can cite your products well, your catalog has to be machine-readable, internally coherent, and easy to trust.
That's why traditional ecommerce SEO is now table stakes. The next layer is earning inclusion in AI-generated answers, product comparisons, and recommendation summaries. If you sell online, you're no longer optimizing only for blue links. You're optimizing for extraction, citation, and recommendation. That changes how product pages should be written, how category architecture should be built, and how you measure success.
The good news is that the underlying disciplines overlap. The same teams that get structured product data right, localize cleanly, and publish strong comparison content tend to be the teams that show up more often in AI responses. The difference is that you now need to think in terms of prompts, citations, and answer engines in addition to rankings and sessions.
If you're building that bridge now, it helps to pair classic ecommerce fundamentals with AI-specific workflows. That's where modern AI strategies for B2B ecommerce vendors start to matter. The checklist below focuses on what moves the needle for both search engines and AI systems.
1. Optimize Product Pages for AI Search Intent and Citation
The ecommerce teams that win AI visibility do not publish prettier product pages. They publish clearer ones. If ChatGPT, Gemini, or Google's AI features cannot extract the product facts, trade-offs, and use cases from your page with confidence, your SKU is less likely to be cited in recommendations, comparisons, and shopping answers.
As noted earlier in Google's guidance, product pages need machine-readable facts that match what users see on the page. The operational problem is usually not missing content. It is scattered content. Specs sit in tabs loaded late, shipping details live in a help center, variant names are inconsistent, and schema no longer matches the offer shown to shoppers.
What AI systems need from a product page
AI systems cite pages that answer a product question cleanly. That means the page has to do more than describe the item. It has to state what it is, who it fits, what makes it different, what constraints matter, and what a buyer should know before purchase.
Retail leaders like Amazon and Best Buy are useful reference points here. Their strongest pages make core facts easy to parse in plain HTML, and they reduce ambiguity around compatibility, included parts, delivery timing, and return expectations. That improves conversion. It also improves the odds that an AI system can reuse the page as a citation instead of looking elsewhere.
A product page built for citation usually includes:
Exact product naming: Put the brand, model, size, color, and variant details in the title and near the top of the page.
Readable specs: Publish dimensions, materials, compatibility, SKU, GTIN, and included components in crawlable HTML, not only in images or buried accordions.
Decision support: Answer common pre-purchase questions directly on the page, especially fit, setup, maintenance, and usage limits.
Commercial clarity: Keep price, availability, shipping windows, and returns consistent across visible copy, feeds, and schema.
Clear differentiation: State the trade-offs. If the product is lighter, quieter, cheaper, or more durable than alternatives, say so plainly.
One test works well. Ask whether the page can support an AI answer to: “What is this product, who is it for, why would someone choose it, and what should they know before buying?” If any part is vague, the page is underprepared for GEO.
For teams treating this as a measurable channel, citation tracking matters more than rank tracking alone. Spotlight's free GEO and AEO tools for agencies focused on AI search optimization are useful for checking whether product URLs appear in AI-generated answers by market and prompt type.
One caution. Longer copy does not automatically produce more citations. In practice, pages with sharper facts, stronger attribute coverage, and clearer buyer-fit language often outperform pages padded with generic feature text.
2. Implement Geo-Specific Content for Multi-Market AI Visibility
A product page that works in the United States often underperforms in Canada, the UK, or Australia even when the core SKU is identical. The copy may be technically translated, but the page still feels wrong for the market. AI systems pick up that mismatch fast because prompts often contain regional context.
The fix isn't just changing currency. Strong multi-market pages localize terminology, sizing, shipping expectations, return language, and payment context. Uniqlo-style regional storefronts work because they don't pretend one version of the catalog fits every audience.
Localization that helps citation, not just translation
The most common mistake is publishing duplicated local pages with only light edits, then leaving search engines to sort out the intended market. That confuses traditional search and AI citation alike. Hreflang, canonical logic, and market-specific copy need to work together.
If you're testing this operationally, tools for geo validation matter as much as the pages themselves. Spotlight's regional testing workflow is useful for teams that want to see how AI visibility changes by country, and its roundup of free geo and AEO tools for agencies focused on AI search optimization is a practical starting point.
Use geo pages to make local realities explicit:
Market language: “Trainers” and “sneakers” shouldn't fight on the same regional page.
Commercial context: Show local payment methods, duties, shipping windows, and returns where relevant.
Regulatory clarity: Surface region-specific compliance details when they affect purchase decisions.
Local availability: Don't let a global template imply a product can ship everywhere if it can't.
When ecommerce brands get this right, AI systems have a cleaner choice about which market page to cite. When they get it wrong, the model often falls back to a third-party source that explained the local context better.
3. Build Authority Through Content That AI Models Naturally Citation
If you want AI systems to mention your brand in product recommendations, generic blog content is a weak bet. Models cite pages that resolve a question cleanly, show clear selection logic, and give enough specifics to summarize without guessing.
That changes the content brief.
Instead of publishing broad guides built to chase volume, build pages around decision moments. The pages that earn citations usually help a user compare options, choose based on constraints, or understand fit before purchase. On ecommerce sites, that often means buying guides, use-case pages, compatibility explainers, care and maintenance content, and side-by-side comparison pages drawn from your own catalog knowledge.
Wirecutter-style structure works because it exposes reasoning. A model can extract who a product is for, where it falls short, and why an alternative may be better for a different buyer. Brand content should do the same, but with tighter product expertise and cleaner commercial context.
For GEO, authority is less about sounding polished and more about being quotable. The strongest pages make claims in a format AI systems can reuse: clear headings, explicit criteria, concise summaries, and evidence that comes from real product knowledge rather than filler copy.
Build your content mix around citation-friendly intents:
Choice support: “How to choose the right trail running shoe for rocky terrain”
Use-case guidance: “Best office chair materials for 8-hour sitting”
Constraint-based recommendations: “Best strollers for small car trunks”
Comparison content: “Hybrid mattress vs memory foam for hot sleepers”
Compatibility answers: “Which water filter fits older Brita pitchers”
The trade-off is operational. Thin content is faster to produce, but it rarely becomes the source an AI assistant trusts for a recommendation. Citation-focused content takes merchandiser input, customer support insights, and product-level detail. It also tends to perform better across both classic SEO and AI discovery because it answers the exact question instead of circling it.
I've found the highest-yield workflow is to mine the questions your team already hears. Pull from on-site search, pre-sales chat logs, returns reasons, support tickets, and review themes. Then turn those into pages with a clear point of view and direct recommendation criteria. If the page could help a shopper make a choice even after reading only the AI summary, it is built on the right standard.
Measurement matters here too. GEO content should be tracked by whether it gets cited, paraphrased, or used in AI comparison answers, not only by organic sessions. Teams using platforms like Spotlight can monitor which pages show up in AI-generated responses by prompt type, then expand the formats that keep getting referenced.
If reviews are part of the evidence base behind these pages, connect the workflow to collection. Review Overhaul's review solutions can help teams generate more detailed customer feedback, which gives comparison and use-case content stronger proof instead of recycled brand claims.
4. Leverage Product Reviews and User-Generated Content for AI Credibility
AI systems are conservative when product claims look one-sided. Pages with only brand-authored benefits and no customer proof feel less trustworthy than pages that include reviews, Q&A, and visual evidence from real buyers.
That doesn't mean review quantity alone wins. What helps most is specificity. A review that says a running shoe felt stable on long pavement runs is more useful than a review that says “Great product.” The same goes for apparel, furniture, skincare, and electronics. Details make reviews extractable.
Turn reviews into structured proof
Google recommends keeping product page signals aligned with visible content and explicitly highlights details such as price, availability, reviews, shipping, and returns. OuterBox also summarizes that the most important structured fields often include product name, brand, SKU or GTIN or MPN, price, currency, availability, aggregate ratings, shipping and return details, and variant relationships in its guide to ecommerce SEO strategies.
That's why review handling should be operational, not cosmetic:
Collect reviews that answer real questions: Ask buyers about fit, durability, setup, compatibility, and intended use.
Mark them up properly: Use review schema only for actual on-page reviews, not manufactured summaries.
Feature useful formats: Photo reviews and comparison comments often add more confidence than star icons alone.
Respond when needed: A thoughtful brand response can clarify edge cases, shipping confusion, or usage guidance.
A lot of brands also underestimate post-purchase workflows. If you want stronger review content, ask better prompts after delivery. For teams reworking that pipeline, Review Overhaul's review solutions are worth examining as an operational model.
5. Optimize for AI-Specific Search Queries and Natural Language Variation
Traditional keyword research still matters, but AI prompts expose a layer of demand that standard term lists often flatten. People don't only ask for “best office chair.” They ask for the best office chair for lower back pain in a small apartment, or whether one brand is better than another for all-day work.
That shift changes page design. You need content blocks that address use case, comparison, constraints, and buyer type directly. Product pages, collection pages, and editorial pages should each absorb a different class of prompt.
Map prompts to page types
Industry guidance summarized by Grumspot emphasizes transactional and long-tail keyword targeting, with workflows in Semrush and Ahrefs built around intent, volume, competition, and page mapping. One practical benchmark in that guidance is prioritizing terms with at least 100 monthly searches while treating longer, more specific queries as stronger buying signals, as described in its article on ecommerce SEO best practices.
That benchmark is helpful, but don't force every conversational prompt into a new page. Most stores need a cleaner map:
Category pages for broad commercial demand
Filter or collection pages for attribute-led demand
Product pages for exact product and variant intent
Editorial content for comparisons, use cases, and decision support
I've found the strongest AI search programs build reusable prompt patterns into templates. They don't treat every new natural-language query as a custom content project. They identify recurring structures like “best for,” “under budget,” “vs,” and “for beginners,” then build pages that can credibly answer them.
6. Build Internal Linking Architecture for AI Model Navigation and Understanding
Internal linking is where many ecommerce SEO best practices either scale or collapse. A well-linked catalog tells a search engine and an AI system how products, categories, and supporting content relate. A poorly linked catalog leaves valuable pages stranded.
This gets worse as the store grows. Merchandisers launch new categories, filters multiply, seasonal pages appear, and no one revisits the underlying architecture. The result is familiar: orphaned pages, weak category hubs, and random link placement driven by CMS convenience rather than strategy.
Architecture beats isolated page optimization
Amazon's category hierarchy remains the reference example because it links products, subcategories, alternatives, and related behavior patterns in a coherent way. You don't need Amazon's scale to borrow the principle. Every important product type should sit inside a clear hub-and-spoke structure.
A practical internal linking pass usually includes:
Repair orphaned URLs: Make sure priority products are linked from relevant category and subcategory pages.
Strengthen breadcrumbs: Breadcrumbs clarify hierarchy for users and machines.
Link to decision content: Product and category pages should connect to buying guides and comparisons where that helps the shopper.
Use descriptive anchors: “Men's waterproof trail running shoes” is better than “shop now.”
The best internal links don't just pass authority. They explain the catalog.
There's a trade-off here too. Teams sometimes overlink every page to every other page in the name of discoverability. That muddies hierarchy and weakens signal clarity. Better architecture is selective. It shows which paths matter most.
7. Optimize Page Speed and Technical SEO for AI Crawler Efficiency
Fast pages help shoppers, but they also help machines process your site with less friction. If templates are bloated, critical content loads late, or key product data depends on fragile client-side rendering, you're increasing the chance that search engines and AI systems get an incomplete picture of the page.
Technical SEO remains foundational because ecommerce sites produce a lot of complexity by default. Variant URLs, faceted parameters, pagination, and seasonal inventory churn can create thousands of weak or duplicate pages quickly. That's why Google's guidance treats canonicalization and index control as core ecommerce work, not cleanup work.
Technical hygiene that affects discoverability
The pages most likely to cause trouble are often not the ones teams watch most closely. They're filtered listings, internal search pages, expired products, and parameter combinations that create thin duplicates.
A disciplined technical pass should cover:
Render essential content in accessible HTML: Don't hide core product facts inside scripts when you can avoid it.
Control duplicate paths: Use canonical tags and noindex rules where pages don't deserve independent visibility.
Keep mobile templates clean: Many crawlers and users encounter the mobile experience first.
Audit faceted navigation: Parameters should serve user discovery without creating uncontrolled index sprawl.
One hard truth in ecommerce is that better content can't rescue a catalog the crawler can't interpret cleanly. Before you chase new GEO experiments, make sure your technical base isn't subtly suppressing the pages you most want cited.
8. Create Competitor Analysis Content That AI Models Use for Comparisons
Comparison content is one of the clearest bridges between classic SEO and AI search. Users ask models direct judgment questions all day long: which laptop is better for students, which espresso machine is easier to maintain, what's a good alternative to a premium brand.
If your site never addresses those questions, the model will source the answer elsewhere. Usually from publishers, marketplaces, forums, or review sites that were willing to make the comparison you avoided.
Comparison pages need editorial judgment
The best comparison pages don't read like sales pages with two logos pasted at the top. They define the buyer, the use case, and the trade-offs. PCPartPicker and Capterra-style experiences work because they help a shopper decide, not because they mention competitors more often.
Useful comparison content should include:
A clear scenario: Better for travel, better for gaming, better for beginners, better for wide feet.
Objective criteria: Specs, compatibility, limitations, maintenance, support, or setup complexity.
Honest negatives: If your product is stronger in one context but weaker in another, say it.
Recommendation logic: Explain who should choose which option and why.
Many in-house teams often hesitate at this point. Legal or brand teams may worry about naming competitors. But if buyers are already asking AI systems for that comparison, silence doesn't protect your brand. It just hands the narrative to someone else.
9. Monitor and Respond to Brand Mentions in AI Systems Through Citation Tracking
AI visibility can drift long before revenue does.
A brand can keep ranking for category terms while losing share inside ChatGPT, Gemini, and other answer engines because the model stopped citing its pages, started citing a competitor more often, or picked up the wrong framing from reviews, reseller listings, or third-party commentary. If you only watch sessions and rankings, you see the lagging signal. Citation tracking gives you the earlier one.
AI systems do more than mention a URL. They summarize your brand position. They decide whether you are premium or overpriced, beginner-friendly or complex, credible or interchangeable. Those descriptions shape consideration before the click.
For ecommerce teams shifting from classic SEO to GEO, the job is to monitor three things at once: whether your brand appears, which sources the model cites, and how the model describes you. Spotlight's guide to tracking brand mentions in AI chatbots is a useful operational reference for building that workflow, and its analysis of which schema markup types appear in AI-cited websites helps connect mention tracking to the on-page signals that often support citation.
A workable review process usually includes:
Prompt sets by intent: Separate discovery, comparison, post-purchase, and problem-solving prompts. Models often cite different sources for each.
Brand versus competitor share: Track where rivals appear in answers and cited links, especially for “best,” “alternative,” and “vs” queries.
Narrative patterns: Save recurring phrases tied to your brand, products, pricing, quality, and support experience.
Source diagnosis: Check whether the model is pulling from your site, retailers, forums, review publishers, or outdated pages.
Response priorities: Fix pages that feed bad summaries first. Usually that means product detail pages, FAQs, comparison content, and review surfaces.
The trade-off is straightforward. Manual prompt checking gives useful qualitative insight, but it breaks down fast across markets, product lines, and prompt variations. Platform-based tracking is better for trend detection and competitor benchmarking, but it still needs human review because citation presence alone does not tell you whether the model framed your brand well.
Offsite reputation also matters here. If AI systems keep surfacing third-party commentary ahead of your own pages, understanding how brand mentions SEO works helps tie GEO monitoring to digital PR, review generation, and publisher outreach.
Treat citation tracking as a weekly operating rhythm, not a quarterly audit. The goal is not just more mentions. It is better mentions, from better sources, in the prompts that influence buying decisions.
10. Integrate Structured Data and Schema Markup for AI Model Understanding
Structured data gives AI systems a cleaner read of your catalog. On ecommerce sites, that affects more than rich results. It shapes whether a model can identify the product, connect it to the right offer, and pull the same facts your team wants surfaced in AI answers.
Accuracy matters more than volume. Schema should confirm what the page already states in visible copy. If your markup says a product is in stock, priced at one amount, or tied to a specific rating while the page says something else, you create conflicting signals. That weakens trust for search engines, AI systems, and buyers.
The priority is straightforward. Mark up the facts that change buying decisions and citation quality:
Product schema for product identity, including name, brand, SKU, GTIN, or MPN
Offer or AggregateOffer markup for price, currency, and availability
Review and rating schema where real customer feedback exists
Shipping, returns, and merchant policy details when those terms influence purchase confidence
Variant relationships so size, color, or model versions are understood as related options, not separate duplicate pages
This is where implementation discipline matters. Many teams publish schema once, then let feed updates, merchandising edits, or frontend changes break it. A strong setup includes recurring validation, ownership between SEO and engineering, and alerts for mismatches between page content and markup.
For GEO, the trade-off is practical. Schema alone will not get a product cited by ChatGPT or Gemini if the page lacks useful content, reviews, or brand authority. But clean markup improves machine readability, reduces ambiguity, and gives AI systems more confidence in the core facts they summarize. Teams tracking AI visibility in platforms like Spotlight should connect schema changes to citation movement by page type, product line, and query pattern, especially after large catalog updates.
Use schema to remove guesswork. Then keep it synchronized so your product data stays citation-ready.
10-Point AI-Focused Ecommerce SEO Comparison
Strategy
Implementation complexity
Resource requirements
Expected outcomes
Ideal use cases
Key advantages
Optimize Product Pages for AI Search Intent and Citation
3–5x higher citation rates for conversational queries
Brands targeting question-driven purchase intent
Targets real AI prompts with lower competition
Build Internal Linking Architecture for AI Model Navigation and Understanding
Medium, site audit and restructure
SEO audit, content updates, developer support
Better AI understanding and discoverability in 4–6 weeks
Large catalogs and content-rich sites
High impact on topical relevance with relatively low effort
Optimize Page Speed and Technical SEO for AI Crawler Efficiency
Medium–High, technical optimizations
Developers, performance tooling, CDN
Faster crawling and more consistent AI citations (2–4 weeks)
Sites with heavy JS or slow load times
Foundation for crawlability, UX, and AI access
Create Competitor Analysis Content That AI Models Use for Comparisons
Medium, structured comparison content
Competitive research, content templates, updates
Higher citations for comparison queries; traffic from alternatives
Markets with many comparable products
Captures high-intent comparison traffic and trust
Monitor and Respond to Brand Mentions in AI Systems Through Citation Tracking
Low–Medium, tool setup and workflows
Citation tracking tool, analysts, reporting
Faster detection of citation shifts and actionable insights
Brands monitoring AI reputation and performance
Real-time visibility to inform rapid strategy changes
Integrate Structured Data and Schema Markup for AI Model Understanding
Medium, technical markup work
Developers, schema validators, QA
Improved citation accuracy and rich results (weeks)
Sites with products, reviews, and FAQs
Machine-readable content that boosts AI extraction and accuracy
From Checklist to Competitive Advantage
The phrase “ecommerce SEO best practices” can sound stale because the basics have been common knowledge for years. Research keywords. Write product copy. Fix technical issues. Add schema. Improve speed. None of that is wrong. It's just incomplete now.
What changed is the surface area of discovery. Your brand no longer competes only for rankings in a conventional SERP. It competes for inclusion in AI-generated answers, follow-up recommendations, product comparisons, and conversational shopping journeys. That doesn't replace classic SEO. It raises the standard for it.
The strongest ecommerce teams are treating SEO and GEO as one operating system. They don't separate “ranking work” from “AI work” because the underlying requirements overlap. Clean product entities, strong category structure, selective indexation, credible reviews, comparison content, and market localization all make the site easier for machines to understand. Once that foundation is in place, AI citation becomes a measurable extension of good ecommerce execution rather than a mysterious black box.
The underserved opportunity is selective depth. Most stores still spread effort too evenly across the catalog. They optimize thousands of pages lightly instead of identifying the pages and page types most likely to influence both search and AI recommendations. That usually means top category pages, high-margin products, comparison pages, and localized market pages. Those assets deserve stronger copy, cleaner data, better internal links, and active measurement.
Faceted navigation is a good example of where old habits need updating. Many teams still default to blocking filters broadly because they're worried about duplication. The more practical approach is selective indexation based on real demand. Major Tom's discussion of faceted navigation in ecommerce SEO points to the right operational question: which filter combinations deserve visibility because shoppers search for them? When you answer that with demand data, not fear, filter pages can become some of the best assets in the catalog for high-intent discovery.
If you need a starting point, don't start with everything. Start with your top product pages. Tighten the facts, strengthen the schema, add decision-support copy, and make sure price, availability, shipping, and returns are easy to extract. Then monitor how those pages appear across AI systems. After that, move into comparison content, localized pages, and faceted page governance.
That's how this becomes a competitive advantage instead of another audit document. You pick the pages that matter, make them easier for machines to trust, and measure whether models cite them. Over time, that compounds into stronger visibility in both traditional search and AI-driven commerce.
Spotlight Group LLC helps SEO, content, and growth teams turn AI search from a black box into a measurable channel. If you want to see where ChatGPT, Gemini, Perplexity, Claude, Copilot, Grok, AI Overviews, and AI Mode mention your brand, which prompts trigger those mentions, and which sources models cite, Spotlight Group LLC gives you the workflow to monitor, prioritize, and improve that visibility.
Most advice about search engine optimization using AI is wrong in the same way. It treats AI as a cheaper writer.
That mindset produces more pages, more sameness, and more reporting that still depends on rankings and clicks. It misses the operational change that matters. Search teams now need to optimize for whether AI systems select, summarize, and cite their content, then prove that visibility influenced pipeline even when nobody clicked.
The useful question isn't “how do we publish faster?” It's “how do we become the source the model uses, and how do we measure the business impact when the answer is delivered inside the interface?”
The content mill version of AI SEO is already stale. Teams that only use AI for drafting usually end up with a larger editorial backlog, a thinner review process, and very little improvement in actual market visibility.
The workflow that works looks different. It starts with prompt discovery, entity mapping, citation analysis, retrieval-friendly content structure, and measurement. Writing is only one step in that chain.
Semrush reported that almost 70% of businesses said they had seen higher ROI after integrating AI into SEO. The same Semrush analysis noted that Google AI Overviews reached 2 billion monthly users and roughly 60% of searches now yield no clicks. That combination is why old rank-and-click reporting is breaking down. If the user gets the answer in the interface, visibility still happened. Your standard dashboard may not show it clearly.
What the workflow actually changes
A modern AI SEO workflow shifts effort from bulk production to answer design:
Research changes first: Teams mine query variants, related entities, and repeated user questions instead of building briefs around one exact-match keyword.
Pages become retrieval assets: The page has to work at passage level, not just page level. That means headings with clear scope, concise answers near the top, and support details underneath.
Success metrics change: Rankings still matter, but citation frequency, mention quality, prompt coverage, and branded presence inside AI responses matter more than they used to.
Practical rule: If your process can generate articles but can't tell you which prompts trigger your brand in AI answers, the workflow is incomplete.
This is why broad “publish more with AI” advice usually disappoints experienced teams. AI amplifies weak strategy just as fast as it amplifies strong strategy.
For eCommerce teams especially, the tactical overlap with product discovery is worth studying. NanoPIM's guide to generative AI for eCommerce is useful because it frames optimization around how AI surfaces products and brands, not just how pages rank.
What still doesn't work
A few patterns keep failing in practice:
Generic top-of-funnel articles: They're easy to generate and hard to cite.
Keyword insertion without answer depth: Models don't reward shallow coverage dressed up with semantically related terms.
Reporting that stops at traffic: That misses exposure happening inside AI systems before the visit, branded search, or assisted conversion.
The new workflow is narrower, stricter, and more measurable. That's a good thing.
Auditing Your Visibility in AI Search
Before changing content, audit your current presence. Many practitioners skip this because traditional SEO habits push them straight into optimization. In AI search, that usually creates waste.
You need to know where your brand appears, which prompts trigger those appearances, how competitors show up in the same prompt sets, and whether the models cite you, summarize you, or ignore you.
Start with prompt sets, not keyword lists
Keyword tracking alone won't show how people phrase questions inside ChatGPT, Gemini, Perplexity, Copilot, or AI Overviews. Build prompt groups around real buying and research behavior.
Problem prompts: “How do I fix…”, “what causes…”, “why does…”
Comparison prompts: “X vs Y”, “better than”, “which is best for”
Brand prompts: Your company name, product names, executive names, and branded use cases
This work is more like demand mapping than classic rank tracking. The point is to see the conversation surface, not just the search result page.
Capture the answer, not just the mention
When your brand appears, log more than yes or no. Capture the response structure.
Use an audit sheet that records:
Audit field
What to capture
Prompt
The exact user-style prompt entered
Model
ChatGPT, Gemini, Perplexity, Copilot, AI Overviews, or another system you monitor
Brand appearance
Mentioned, cited, summarized without citation, or absent
Position in answer
Lead recommendation, supporting mention, comparison entry, or footnote-style citation
Narrative
Positive, neutral, inaccurate, incomplete, or competitor-led framing
Source pattern
Which domains the model appears to rely on
That narrative field matters. A brand can have visibility and still lose the interaction if the model frames the category around a competitor or surfaces outdated positioning.
An AI visibility audit should answer two questions fast: “Do we appear?” and “What story does the model tell when we do?”
Check where the model learned the answer
Many SEO teams often discover their first useful surprise: The page you expect to influence the answer often isn’t the page doing the work. Sometimes a glossary page, help doc, product comparison, Reddit thread, or third-party review shapes the response more than the polished landing page.
Don’t benchmark every prompt equally. Prioritize prompts that map to revenue motion.
For example:
Buyer-intent prompts show whether you’re present when users compare vendors.
Category-definition prompts reveal whether you own the language around your market.
Support and trust prompts show whether users encountering your brand get reassured or redirected.
One useful tool category here is AI visibility monitoring platforms. Spotlight, for example, tracks brand mentions, prompts, and citation sources across major AI platforms. Teams also combine that type of monitoring with GA4, Search Console, manual prompt testing, and sales-call notes to connect presence with outcomes.
An audit gives you a baseline. Without that baseline, “search engine optimization using AI” turns into guesswork with better software.
Prompting Content That Earns AI Citations
Citable content starts long before drafting. The prompt that creates the brief matters more than the prompt that writes the paragraph.
The job is to reverse-engineer the answer space. What questions appear repeatedly? What subtopics are missing from current pages? Which definitions, comparisons, and caveats make a model more likely to treat your page as usable source material?
BrightEdge notes that pages directly addressing specific user queries achieve 31% higher citation rates in AI-generated results. That changes how briefs should be built. Explicit question coverage is not a formatting preference. It’s a performance lever.
Build briefs from question clusters
Single-keyword briefs underperform because they compress different intents into one target phrase. AI systems don’t retrieve content that way. They assemble answers from passages that clearly address distinct questions.
A stronger briefing sequence looks like this:
Collect the query set Pull search terms, customer questions, support tickets, sales-call objections, community threads, and prompt variants from AI platforms.
Group by intent and entity Separate definitions from comparisons, workflows from pricing questions, and beginner questions from evaluative ones.
Draft a passage map Decide which section answers which question. Don’t let one section try to do too much.
Add source demands Mark every claim that needs verification, examples, or first-hand explanation before drafting starts.
Use prompts to create structure, not finished prose
Teams often over-prompt for style and under-prompt for coverage. That’s backward.
A productive content brief prompt asks AI to produce:
key questions users ask about the topic
related entities and attributes that need mention
a heading structure that answers those questions in logical order
missing subtopics competitors often skip
likely objections, caveats, or decision criteria
Then a human editor tightens the brief, adds product truth, removes generic filler, and sets factual guardrails.
Here’s the standard I use: if the brief doesn’t tell the writer what each section must answer, it isn’t a brief. It’s a topic suggestion.
Format for retrieval, not only readability
Good human UX and good retrieval formatting usually align, but not always. AI systems favor passages that are self-contained and easy to lift into an answer.
That means your page should include:
Direct-answer openings: Answer the heading immediately, then expand.
Scoped subheads: Write headings that signal a complete topic, not vague labels.
Tight comparison sections: Present criteria cleanly so the model can reuse them.
Visible definitions: Don’t bury category basics under long intros.
Selective Q&A blocks: Useful when the question is common and the answer can stand alone.
A detailed tactical resource here is Spotlight’s guide on how to get ChatGPT to cite your content, especially if your team needs examples of citation-oriented structure.
Write every major section so it can survive extraction. If a paragraph loses meaning when pulled out of context, it’s less likely to become a cited passage.
What usually breaks citation potential
The most common failures are operational, not creative.
Weak pattern
Why it fails
Long intros before the answer
The model finds a clearer passage elsewhere
Broad headings like “Benefits”
Weak retrieval signal because scope is unclear
Repetitive SEO copy
Reads as optimized text, not source material
Unsupported claims
Increases editorial risk and weakens trust
FAQ spam
Too many low-value questions dilute the page
The strongest pages don't sound “AI-written.” They sound like a knowledgeable operator answered the exact questions a buyer or researcher would ask, in the order they'd ask them.
On-Page Optimization Signals for AI Models
Traditional on-page SEO still matters. If a page is hard to crawl, poorly organized, or disconnected from the rest of the site, AI systems won't suddenly rescue it.
What changes is the unit of evaluation. AI systems often work with chunks, passages, and structured clues. A strong page gives them clean extraction points, clear meaning, and enough contextual depth to trust the answer.
Signals that improve machine interpretation
The pages that earn mentions consistently tend to share a few traits.
Clear heading hierarchy: Each H2 and H3 should describe a distinct subtopic. Vague headers force the model to infer too much.
Early answer placement: Put the answer near the top of the section, then expand with examples, edge cases, and trade-offs.
Entity completeness: Name the core tools, concepts, audiences, alternatives, and attributes tied to the topic.
Internal linking with purpose: Link related pages because they deepen topical context, not because a plugin suggested anchor text.
Schema where it adds clarity: FAQ, HowTo, Product, Organization, and Article markup can help machines classify the page more cleanly.
A lot of teams hear “optimize for AI” and immediately chase exotic tactics. Most gains still come from disciplined page construction.
Passage-level optimization is the real shift
A ranking-era page could get by with one strong title, some backlinks, and acceptable topical coverage. AI-mediated discovery is less forgiving. The model may only use one paragraph from your article.
That changes editorial standards.
Consider the difference:
Weak passage
Strong passage
Talks around the question
Answers it in the first sentence
Uses broad marketing language
Uses concrete, scoped language
Depends on earlier context
Makes sense as a standalone excerpt
Hides key detail in visuals
States the key detail in HTML text
Make expertise legible
A page can be accurate and still look generic. That's often an authoring problem.
Use visible trust signals such as:
named authors or editors where appropriate
clear publication and update context
cited sources when the topic requires verification
examples from implementation, support, operations, or customer education
language that acknowledges limits, exceptions, and trade-offs
Strong AI-visible pages don't just contain expertise. They display it in ways a machine can parse and a user can trust.
What to remove
Some page elements subtly hurt AI usability:
Accordion-heavy pages that hide critical answers
Image-only explanations without HTML equivalents
Decorative intros that delay the useful part
Template repetition that makes every section sound the same
Thin comparison tables with labels but no interpretation
The target is clarity with substance. If a page is easy to parse but says little, it won't win. If it says a lot but is structurally messy, it won't get selected reliably either.
Measuring ROI from AI Mentions and Citations
Most AI SEO advice frequently falters. It tells teams how to produce and optimize content, then stops before the finance question.
The hard part isn't getting an AI mention. The hard part is proving that mention created business value when the user may never click.
That measurement gap is real. As LLMrefs points out, a major underserved topic in AI SEO is how to measure ROI, because most guidance explains optimization tactics but not how to connect AI citations and brand mentions to business value when traditional click-based metrics are absent.
Start with an influence model, not a last-click model
If you treat AI visibility like paid search with missing referral data, you'll misread the channel.
A better approach is to model influence across four layers:
Layer
What to observe
Presence
Does your brand appear for important prompts
Quality
Are you cited, recommended, or merely mentioned
Action
Do users search your brand, visit direct, or arrive through cited referral paths
Outcome
Do those sessions contribute to pipeline, qualified leads, or revenue
This is closer to how PR, brand search, and analyst influence have always worked. AI search just makes the blind spot larger.
Use proxy metrics that connect to revenue motion
Not every useful metric is a final outcome metric. Some are leading indicators.
The most practical ones include:
Citation frequency by prompt cluster: Shows whether your content is winning inclusion in commercially relevant topics.
Branded prompt share: Reveals whether users ask for your brand by name inside AI interfaces.
Referral patterns from citable engines: Some AI products pass source traffic more clearly than others.
Lift in branded search behavior: Often one of the clearest signals that AI exposure is pushing users back into searchable demand.
Sales-team hearing rate: If prospects increasingly mention having “seen” or “asked AI” before a demo, log it.
This broader framing aligns with the older SEO concept of share of voice, but the measurement object changes. If your team already uses search visibility models, adapting them to AI answer surfaces is a sensible next step. Spotlight's piece on share of voice SEO is useful here because it helps frame visibility as a market-level measure rather than a page-level vanity metric.
Tie prompts to journeys
The smartest reporting I've seen maps prompt classes to funnel stages.
For example:
category education prompts map to early awareness
alternatives and comparison prompts map to active evaluation
implementation, pricing, and migration prompts map to purchase readiness
support and trust prompts map to retention and expansion
That lets teams answer a more useful question than “did AI traffic convert?” They can ask, “where in the journey does AI visibility influence buyers, and which prompt clusters correlate with downstream conversion behavior?”
If you can't connect AI mentions to a buyer journey, you'll default back to rankings because they feel easier to explain.
Build a reporting cadence your leadership will trust
A workable monthly view includes:
key prompt clusters monitored
brand appearance and citation trends
competitor comparison for those same prompts
traffic patterns likely influenced by AI citation or brand recall
assisted conversion notes from analytics and sales feedback
content changes shipped and the visibility movement after those changes
That closes the loop from content production to business evidence. It also forces better prioritization. Teams stop publishing for volume and start publishing for measurable prompt coverage.
AI SEO Governance and Common Pitfalls
AI-assisted SEO without governance creates a clean-looking mess. The pages go live faster, but factual drift, inconsistent claims, and diluted brand voice pile up gradually until trust erodes.
A governance model should define who can use AI, where human review is mandatory, what sources are acceptable, how claims are verified, and which pages need legal, product, or subject-matter approval. This is not optional for enterprise teams, regulated categories, or any brand that depends on accuracy.
Common AI SEO Pitfalls and Mitigation Strategies
Pitfall
Description
Mitigation Strategy
Over-automation
Teams publish AI drafts with light editing and assume speed equals output quality
Require editorial review before publication and assign clear approval owners
Generic briefs
Writers get a topic, a keyword, and a word count, but no intent map or question set
Build briefs around prompt clusters, entities, and required answers
Unverified claims
AI inserts statements that sound credible but lack proof
Mark every factual claim for source review before publishing
Brand voice drift
Different teams use different prompts and outputs start sounding inconsistent
Create reusable prompting standards, tone rules, and example libraries
Hidden accountability
Nobody owns post-publication QA, updates, or response monitoring
Assign owners for content quality, model visibility tracking, and refresh cycles
The biggest mistake is treating AI as an author instead of an assistant inside a controlled workflow. Teams that govern inputs, reviews, and measurement usually improve faster than teams that publish more.
Frequently Asked Questions About AI SEO
Common questions and direct answers
Question
Answer
Is AI SEO the same as using ChatGPT to write blog posts?
No. Writing is one use case. AI SEO includes prompt research, content clustering, on-page structuring, citation tracking, and ROI measurement.
Does traditional SEO still matter?
Yes. Crawlability, internal linking, topical authority, and strong page structure still support discovery and selection. AI search adds another layer. It doesn't replace the basics.
Should every page have an FAQ section?
No. Add FAQs when they answer real follow-up questions. Forced FAQs often dilute the page and make it feel templated.
What type of content gets cited most often?
Content that answers specific questions clearly, uses strong heading structure, and covers related context without fluff tends to be more citable.
Can you measure value if AI mentions your brand without a click?
Yes, but not with last-click thinking alone. Track prompt coverage, citation trends, branded search behavior, direct traffic patterns, and assisted conversion signals together.
Which teams should own AI visibility?
Usually SEO leads the work, but content, analytics, PR, product marketing, and compliance often need shared ownership.
Will generative AI replace search engines?
It's more useful to think in layers. AI interfaces increasingly mediate discovery, but search infrastructure still matters underneath. This overview of Generative AI vs. search engines is a helpful framing reference.
A realistic expectation helps. Search engine optimization using AI won’t reward teams for scaling mediocre content faster. It rewards teams that can identify the prompts that matter, create pages that answer them better than competitors, and prove that AI visibility influenced revenue even when the click never happened.
The teams that win this shift won’t separate content from measurement. They’ll treat them as one operating system.
If you need that operating system in practice, Spotlight helps brands monitor AI mentions, prompts, and citations across major AI platforms, then connect that visibility back to business impact.
You're probably seeing this already in your reporting. A few target keywords moved up. Traffic looks stable enough. Yet when sales asks whether the brand is becoming more visible in the market, the ranking report doesn't give a satisfying answer.
That gap gets wider when search no longer means ten blue links. Buyers now discover brands through standard organic listings, paid placements, AI Overviews, and chatbot answers that summarize options before a click ever happens. A rank tracker can tell you where one URL sits for one query. It can't tell you whether your brand is owning the category.
That's where Share of Voice SEO becomes useful. It turns scattered visibility data into a competitive KPI you can compare, benchmark, and act on across the full discovery journey.
A ranking report can make a weak search program look healthy. If you rank well for a handful of terms, the dashboard looks green. But if competitors own the rest of the category, dominate the SERP features, and get cited in AI summaries, your business does not control much attention.
That's the central problem with position-first reporting. It treats each keyword as an isolated win or loss. Buyers don't search that way. They move across comparison terms, product-led queries, alternatives searches, reviews, local intent, and follow-up questions. Your team needs a metric that reflects that broader reality.
Search has also fragmented. A user can see an ad, an AI Overview, a featured snippet, product listings, and an organic result before deciding what to trust. If your brand ranks fifth but is absent from the rest of that page experience, the practical visibility is weaker than the ranking suggests. That's one reason many teams are rethinking old SEO reporting models, especially in light of the great decoupling in modern search behavior.
Rankings tell you where a page appears. Share of voice tells you how much of the market your brand actually owns.
The distinction matters most in competitive categories. One brand may lead on a few head terms while another captures the majority of discovery across comparison queries and answer-style searches. The second brand often has the stronger strategic position even if the first team celebrates more top rankings in a limited list.
Share of voice SEO fixes this by moving the conversation from isolated rankings to market visibility. It gives leadership a single lens for answering a harder question: are we becoming more present where demand is created and captured?
What Is SEO Share of Voice Really Measuring
SEO share of voice measures how much of the searchable demand in a category your brand captures compared with the competitors you track. The percentage matters, but the real value is what sits underneath it: coverage across the queries, SERP features, and discovery surfaces that shape buying decisions.
In a traditional SEO model, teams usually express SOV as visibility share or estimated traffic share. The stronger models weight rankings by search volume and expected click-through rate because a brand showing in position one for a high-intent query carries more market presence than a low-ranking result on a marginal term, as explained in Brandwatch's guide to share of voice.
In 2026, that definition needs to be wider.
A useful SOV model now tracks whether your brand appears across the full search experience: standard organic listings, paid placements, AI Overviews, local packs, product results, featured snippets, and the answer layers that feed conversational search tools. A brand can hold steady organic rankings and still lose practical share of voice if competitors own the paid inventory, the AI summary, and the follow-up questions users see before they ever click.
That is why SOV is not just a rank aggregation metric. It is a market visibility metric. It answers a harder question than “where do we rank?” It answers “how often are we present when demand is being captured, influenced, or redirected?”
The same logic applies in local and regional programs. This guide on calculating local market share is useful because it starts with the right discipline: define the market boundary first, then measure your portion of attention inside that boundary.
Why executives care about this KPI
Leadership teams use SOV because it connects SEO reporting to competitive position and growth potential. A ranking improvement only matters if it changes visibility across the terms and surfaces that bring in qualified demand.
There is also a broader marketing principle behind it. Brands that consistently hold more voice in a category tend to build stronger market position over time. In search, that relationship is never perfectly linear because click behavior varies by SERP layout, brand recognition, and intent. Still, the directional signal is strong enough to make SOV one of the few SEO metrics an executive team can use in planning discussions.
Practical rule: If you can't explain your keyword set, your share of voice number won't survive executive scrutiny.
That is why clean market definition matters so much. A useful SOV model starts with a specific segment, a realistic competitor set, and a clear purpose. If the tracked query set is padded with low-intent informational noise, the metric gets inflated and the decisions that follow get worse.
The teams that use SOV well do one thing differently. They treat it as a measure of category presence across discovery channels, not a prettier rankings report.
How to Calculate Share of Voice in SEO
A rank tracker can show five keywords in positions 1 through 3 and still hide a market-share problem. If those rankings sit on low-volume terms while competitors control the high-intent queries, your report looks healthy and your pipeline does not. That is why SOV needs to be calculated as weighted visibility, not as a simple count of rankings.
Start with the simple version
The base formula is still useful:
Share of voice = (Your brand visibility ÷ Total market visibility) × 100
For an early model, visibility can mean keyword presence. You count how often your domain appears across a defined query set, then divide that by the total appearances from all tracked competitors. It is fast, easy to audit, and good enough to spot obvious gaps.
It also breaks quickly.
A presence-based model treats a marginal ranking and a dominant ranking too similarly. It ignores search demand, click concentration, SERP features, and channel differences. In 2026, that gap matters even more because the same query may produce ten blue links, ads, AI Overviews, shopping units, and chatbot answers that influence the buyer before a click happens.
Use a weighted model for decisions
A stronger calculation weights each keyword by opportunity. In practice, that usually means search volume multiplied by expected click-through rate for the position you hold.
Portent explains this approach as traffic share of voice. The logic is straightforward. A ranking only deserves more credit if it is likely to generate more visibility or traffic.
Use these formulas in a spreadsheet or BI model:
Estimated traffic per keyword = Monthly search volume × CTR for ranking position
Brand visibility = Sum of estimated traffic across all tracked keywords
Market visibility = Sum of estimated traffic for your brand plus all competitors
SEO SOV = Brand visibility ÷ Market visibility × 100
That gives you a traditional organic SOV score. For a modern reporting model, keep the same logic and calculate separate SOV views for paid search, AI Overview presence, and conversational AI citations, then compare them side by side. Teams building that layer usually start with AI search monitoring tools for tracking brand visibility in 2026 because rank tracking alone will not capture those surfaces.
If two brands both appear for a keyword, the brand in the position that wins clicks owns more voice.
A practical workflow
The calculation is simple. The setup determines whether the number is useful.
Step
What to do
What to avoid
Build the keyword set
Group terms by product line, use case, funnel stage, or geography
Combining every informational and commercial query into one score
Select the competitor set
Track domains that repeatedly appear in the same results, including publishers or aggregators if they take visibility
Limiting the list to named business competitors
Capture search context
Pull rank, search volume, SERP features, device, and location
Using a single generic ranking export for every market
Apply weighting
Use CTR curves and adjust for branded vs. non-branded terms when needed
Treating all rankings as equal or using one CTR assumption for every SERP type
Split by channel
Report organic, paid, and AI visibility separately before combining them into an executive view
Forcing everything into one blended number with no explanation
Track the same model over time
Keep the query set and methodology stable for trend analysis
Changing the universe every month and calling it growth
A small keyword set can be managed in a spreadsheet. Once you need segmentation by country, device, intent, or AI surface, use a system that exports clean data and keeps your methodology consistent.
I usually tell teams to build two versions. One is a strict organic SOV model for SEO operations. The second is a broader discovery SOV model that includes paid and AI visibility. The first helps diagnose ranking and content issues. The second is what leadership wants, which is a view of how much category attention the brand owns across the places buyers now discover options.
Tools and Data Sources for SOV Measurement
Good SOV reporting depends less on the formula than on the inputs. If your ranking data is inconsistent, your competitor set is incomplete, or your keyword segmentation is messy, the output won't help your team make decisions.
Traditional SEO platforms
For classic organic SOV, the core tools are still SEO suites like Ahrefs and Semrush. They're useful for tracking rankings, estimating visibility across keyword groups, and comparing domains in overlapping search spaces.
What they do well:
Keyword tracking: Monitor your domain and competitors across a defined keyword set.
Competitive overlap: Surface which domains repeatedly appear in the same SERPs.
Segmentation: Break performance out by location, device, or tag-based keyword groups.
What they don't do well is measure AI-native discovery. They weren't built to tell you whether your brand appears in chatbot recommendations, cited source lists, or generated answer summaries.
AI visibility platforms
That gap matters now because buyers are often forming a shortlist before they ever click through to your site. If your brand gets omitted from AI responses, your standard rank tracker may never show the full loss.
Platforms built for AI visibility solve a different measurement problem. They track prompt-level brand presence, citation sources, recurring competitor mentions, and how often a brand appears across systems like ChatGPT, Gemini, Perplexity, and AI Overviews. If you're evaluating vendors in that category, this review of AI search monitoring tools for tracking brand visibility in 2026 is a practical starting point.
One option in that category is Spotlight, which monitors brand mentions across major AI platforms, surfaces prompt patterns, and shows citation sources tied to visibility. That makes it different from a standard SEO suite, which is mostly focused on pages, keywords, and rankings.
What a modern stack looks like
A useful measurement stack in practice usually looks like this:
SEO suite for organic SOV: Use Ahrefs or Semrush for keyword rankings, competitor overlap, and segmented visibility reporting.
Google Ads for paid visibility: Pull impression-based competitive data for commercial query groups.
AI monitoring platform for AI SOV: Track brand inclusion, prompt-level coverage, and source citations across conversational systems.
Analytics platform for validation: Use GA4 or your attribution stack to connect visibility changes with assisted conversions and downstream traffic patterns.
The point isn't to force everything into one metric. It's to give your team one operating model for measuring visibility across surfaces that buyers use.
Benchmarking SOV Across Organic Paid and AI Search
Share of voice stops being useful when teams compare unlike things as if they're the same. Organic SOV, paid visibility, and AI mention share all describe competitive presence, but they behave differently and should be interpreted differently.
Organic search SOV
Organic SOV is closest to the classic SEO model. You're measuring how much visible demand your brand captures across a defined keyword set.
In practice, benchmark it with nuance:
SERP features matter: A standard rank can understate visibility if you also own snippets, product modules, or other rich placements.
Intent clusters matter more than broad totals: Commercial comparisons, alternatives, and solution queries usually say more about category control than a massive informational list.
Competitor overlap matters: Your real search competitors aren't always your sales competitors.
A healthy organic benchmark isn't one universal number. It's a pattern: your brand should be visible across the query groups that map to evaluation and purchase behavior.
Paid search SOV
Paid SOV is usually closer to impression share thinking. Instead of asking how strongly your content ranks, you're asking how often your ads appeared when they were eligible to appear.
That makes paid SOV more operational. Budget, bidding, ad rank, and campaign structure all change the outcome faster than they do in organic search.
Measuring only links and ignoring recommendation presence
AI search SOV
AI search SOV is newer, but the operating idea is simple. Measure how often your brand appears in generated responses for prompts that matter, whether the mention is positive, neutral, or absent, and which sources the model appears to rely on.
That means your benchmark view should include:
Prompt coverage: Are you present for category, comparison, and recommendation prompts?
Competitive frequency: Which brands get repeatedly surfaced as the default answer?
Citation patterns: Which publishers or owned assets are supporting those mentions?
The benchmark that matters isn’t whether one channel looks good in isolation. It’s whether your brand is present across the moments buyers use to narrow their options.
An Action Plan to Increase Your SEO Share of Voice
Teams usually lose share of voice in one of three ways. They target too many low-value keywords. They leave technical visibility on the table. Or they underestimate how much off-page reputation shapes discoverability in both classic search and AI answers.
Content that takes market share
The best content strategy for SOV is narrower than often expected. Recent guidance argues that broad keyword lists distort the metric and recommends focusing on a small set of high-intent, bottom-of-funnel terms because those better reflect buying intent and business impact, according to BrightEdge’s view on share of voice.
That changes how content teams should prioritize work.
Close commercial gaps first: Build or refresh pages for comparison, alternatives, pricing-adjacent, and use-case queries where competitors repeatedly appear and you don’t.
Consolidate overlap: If multiple weak pages compete for the same commercial intent, merge them into one stronger asset.
Write for retrieval, not just ranking: Clear entities, direct answers, strong headings, and clean source attribution improve the odds that search systems and AI systems can use your content.
For editorial teams, a useful companion resource is this guide on how to optimize content strategy for publishers. It’s especially relevant if your brand depends on topic depth and repeat publication rather than a small set of landing pages.
Technical work that protects visibility
Technical SEO rarely creates SOV on its own, but weak technical execution can suppress it fast. When pages are hard to crawl, duplicate each other, or load poorly enough to erode engagement, your content can’t compete consistently.
Prioritize the fixes that directly support discoverability:
Clean indexation: Remove duplicate or low-value pages that dilute topic ownership.
Strengthen internal linking: Route authority into revenue pages and supporting topic clusters.
Improve structured clarity: Use schema where it helps machines understand entities, products, organizations, and page purpose.
A lot of teams spread technical effort too evenly. Don’t. If a page set maps to your most valuable intent cluster, that’s where technical QA should be toughest.
Off-page signals and reputation
SOV grows faster when your brand is seen as a reliable answer outside your own website. That applies to standard search and even more to AI systems that synthesize information from multiple sources.
Focus on signals that expand trusted presence:
Earn citations in relevant publications: Industry roundups, reviews, partner ecosystems, and expert commentary often shape both click behavior and machine-readable brand associations.
Strengthen brand consistency: Make sure the way your company, product, and category language appear across the web is coherent.
Support subject-matter visibility: Executives, practitioners, and specialists should publish where buyers and analysts already pay attention.
Field note: Brands usually don’t lose share of voice because they lack content volume. They lose it because competitors own the commercial moments that influence selection.
Frequently Asked Questions About Share of Voice
Is share of voice the same as impression share
No. They overlap, but they aren’t the same metric.
Impression share is usually a paid media metric tied to ad eligibility and delivery. Share of voice is broader. In SEO and AI discovery, it describes how much of the available market visibility your brand captures compared with competitors. Paid impression share can be one input into a cross-channel SOV model, but it isn’t the whole thing.
How often should teams measure it
Track it often enough to spot movement, but don’t overreact to noise.
Typically, a weekly collection cadence with monthly reporting works well. Weekly data helps you catch shifts caused by content launches, SERP changes, or competitor moves. Monthly reporting gives leadership a cleaner trend line. If the keyword set is small and highly commercial, shorter review cycles can make sense.
Can smaller companies use SOV effectively
Yes, and they often benefit more from it because it forces focus.
A smaller company shouldn’t try to measure “the whole market” at first. Pick one niche, one service line, or one high-intent query cluster. Track the competitors that appear in that search space. Then use SOV to find where the brand can become the default answer in a narrow but valuable segment.
That’s often more useful than chasing broad visibility with limited resources.
What should be included in an AI-era SOV report
At minimum, include classic organic visibility, paid visibility for your commercial query groups, and AI presence for prompts buyers use during research and evaluation. The report should also show which competitors appear most often and where your brand is absent. That’s what turns SOV from a dashboard metric into a prioritization tool.
If your team needs a practical way to measure visibility beyond rankings, Spotlight is worth evaluating. It’s built for brands that want to track how often they appear across AI search and conversational platforms, understand which prompts trigger mentions, and see the citation sources behind those answers so they can improve coverage with clearer SEO and content decisions.