The buzz around generative AI is impossible to ignore. With McKinsey estimating it could add between $2.6 and $4.4 trillion in value to the global economy each year, it’s no wonder leaders are feeling the pressure to get their strategy right.
But where do you even begin?
We sat down with Dan, one of our in-house experts on LLM SEO, to cut through the noise and map out a practical path forward for any brand navigating this new landscape.
Q1. What’s your advice for a business leader who is just starting to think about what LLMs mean for their company?
Dan: The honest answer? Start with a dose of humility and a lot of measurement. There’s a ton of confident commentary out there, but the truth is, even the people building these models acknowledge they can’t always interpret exactly how an answer is produced. So, treat any strong claims with caution.
Instead of getting caught up in speculation, get a concrete baseline. Ask yourself: for the questions and topics that matter to our business, do the major LLMs mention us? Where do we show up, and how do we rank against our competitors? We call this a “visibility score.” It takes the conversation from abstract theory to a tangible map you can actually work with.
If you’re wondering why this is urgent, two external signals make it crystal clear. First, Gartner predicts that by 2026, traditional search engine volume could drop by 25% as people shift to AI-powered answer engines. That’s a fundamental shift in how customers will discover you.
Second, the investment and adoption curves are only getting steeper. Stanford’s latest AI Index shows that funding for generative AI is still surging, even as overall private investment in AI dipped. Together, these trends tell us that your brand’s visibility inside LLMs is going to matter more and more with each passing quarter.
Q2. Once you know your visibility baseline, what should you do to move the needle?
Dan: Think in two horizons:
The model horizon (slow).
Core LLMs are trained and fine-tuned over long cycles. Influence here is indirect: you need a strong, persistent digital footprint that becomes part of the training corpus. This is where classic disciplines: SEO, Digital PR, and authoritative content publishing still matter. High-quality, well-cited articles, consistent mentions in credible outlets, and technically sound pages are your insurance policy that when the next model is trained, your brand is part of its “memory.”
The retrieval horizon (fast).
This is where you can act immediately. Most assistants also rely on Retrieval-Augmented Generation (RAG) to pull in fresh sources at query time. The original RAG research showed how retrieval improves factuality and specificity compared to parametric-only answers. That means if you’re not in the sources LLMs retrieve from, you’re invisible; no matter how strong your legacy SEO is.
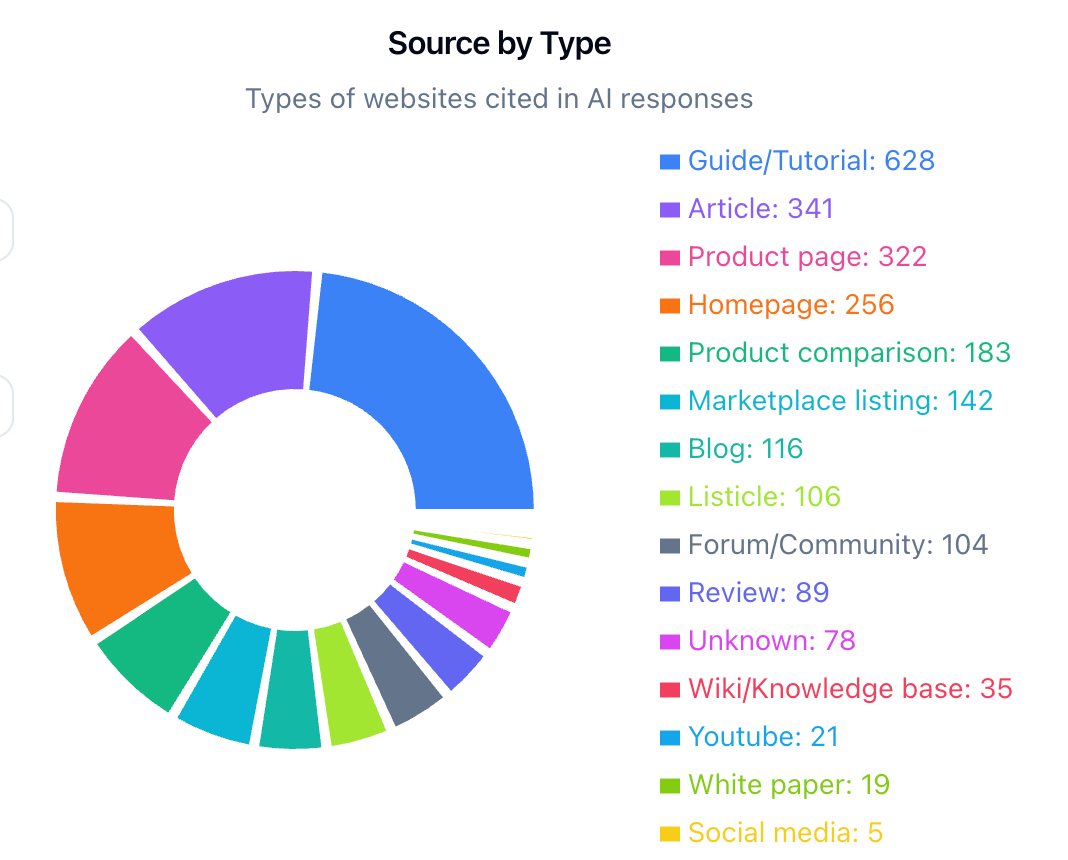
This is why reverse engineering how machines are answering today’s queries is a strategic real-world data point. By mapping which URLs, articles, and publishers are being cited in your category, you uncover the blueprint of what LLMs value: the content structures, schemas, and PR signals they consistently lean on.
From there, your levers become clear:
Digital PR – Ensure your brand is mentioned in trusted publications and industry sources that models are already surfacing.
SEO – Maintain technically flawless pages with schema, structured data, and crawlability, making your content easy for retrieval pipelines.
Content strategy – Match the formats models prefer (lists, tables, FAQs, authoritative explainers), and systematically fill topical gaps.
Analytics – Track citations, rank shifts, and model updates to iterate quickly.
Q3. Let’s say you’ve mapped your visibility, identified the gaps, and set your priorities. What do you do on Monday morning?
Dan: This is where you turn your analysis into action with briefs and experiments.
First, audit what the models are already rewarding. Look at the URLs they cite as sources for answers on your key topics. For each one, study its:
Structure: Does it have clear headings, tables, lists, and direct answers to common questions?
Technical setup: How is its metadata, schema, and internal linking structured? Is it easy to crawl?
Depth and coverage: How thoroughly does it cover the topic? Does it include definitions, practical steps, and well-supported claims?
Doing this at scale can be tedious, which is why we use tools like Spotlight to analyse hundreds of URLs at once and find the common patterns.
Next, create a “best-of” content brief. Let’s say for a key topic, ChatGPT and other AIs consistently cite five different listicles. Compare them side-by-side and merge their best attributes into a single master blueprint for your content team. This spec should include required sections, key questions to answer, table layouts, reference styles, and any recurring themes or entities that appear in the high-ranking sources. You’re essentially reverse-engineering success.
Then, fill the gaps the models reveal. If you notice that AI retrieval consistently struggles to find good material on a certain subtopic; maybe the data is thin, outdated, or just not there; create focused content that fills that void. RAG systems tend to favour sources that are trustworthy, specific, and easy to break into digestible chunks. The research backs this up: precise, well-structured information dramatically improves the quality of the AI’s final answer.
Finally, instrument everything and track your progress. Treat this like a product development cycle:
Track how your new and updated content performs over time in model answers and citations.
Tag your content by topic, format, and schema so you can see which features are most likely to get you included in an AI’s answer.
Keep an eye out for confounding variables, like major model updates or changes to your own site, and make a note of them.
This is critical because the landscape is shifting fast. That Gartner forecast suggests your organic traffic mix is going to change significantly. By reporting on your LLM visibility alongside classic SEO metrics, you can keep your stakeholders informed and aligned. You should get into a rhythm of constant experimentation. The AI Index and McKinsey reports both point to rapid, compounding change. Run small, fast tests: tweak your content structure, add answer boxes and tables, tighten up your citations, and see what moves the needle. Think of 2025 as the year you build your playbook, so that by 2026 you’re operating from a position of strength, not starting from scratch.
Closing Thoughts
Winning visibility in LLMs is about adapting to a fundamental shift in how people access knowledge and how machines assemble information. The path forward starts with three simple questions: Where do you stand today? Which levers can you pull right now? And how do you turn those levers into measurable experiments?
The data is clear: the value on the table is enormous, your competitors are already moving, and the centre of gravity for discovery is shifting toward answer engines. The brands that build evidence-based content systems and learn to iterate in this new environment will gain a durable advantage as the market resets.
Evidence & Sources
- $2.6–$4.4T in Annual Value: McKinsey estimates generative AI could add this much value per year across 63 different use cases. Source: McKinsey & Company, “The economic potential of generative AI: The next productivity frontier,” June 2023. https://www.mckinsey.com/capabilities/mckinsey-digital/our-insights/the-economic-potential-of-generative-ai-the-next-productivity-frontier
- Search is Shifting to Answers: Gartner forecasts that traditional search engine volume will drop by about 25% by 2026 as users move to AI chatbots and agents. Source: Gartner, “Gartner Predicts Search Engine Volume Will Drop 25 Percent by 2026,” April 2024. https://www.gartner.com/en/newsroom/press-releases/2024-04-17-gartner-predicts-search-engine-volume-will-drop-25-percent-by-2026-due-to-ai-chatbots-and-other-virtual-agents
- Enterprise Adoption is Real: IBM’s Global AI Adoption Index reports that 42% of large companies have already deployed AI, with another 40% in the exploration or experimentation phase. Source: IBM, “Global AI Adoption Index 2023,” January 2024. https://newsroom.ibm.com/2024-01-17-IBM-s-Global-AI-Adoption-Index-2023-Finds-AI-Adoption-is-Steady,-But-Barriers-to-Entry-Remain-for-the-40-of-Organizations-Still-on-the-Sidelines
- GenAI Investment Keeps Surging: Stanford HAI’s 2024 AI Index Report found private investment in generative AI soared in 2023, reaching $25.2 billion—nearly 8 times the investment level of 2022. Source: Stanford University, “Artificial Intelligence Index Report 2024,” April 2024. https://aiindex.stanford.edu/report/
- Why RAG Matters: The original Retrieval-Augmented Generation research showed that models produce more specific and factual answers when they can pull in fresh, retrieved sources—a foundational concept for any near-term brand visibility strategy. Source: Lewis, et al., “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks,” May 2020. https://arxiv.org/abs/2005.11401