
Most advice about search engine optimization using AI is wrong in the same way. It treats AI as a cheaper writer.
That mindset produces more pages, more sameness, and more reporting that still depends on rankings and clicks. It misses the operational change that matters. Search teams now need to optimize for whether AI systems select, summarize, and cite their content, then prove that visibility influenced pipeline even when nobody clicked.
The useful question isn't “how do we publish faster?” It's “how do we become the source the model uses, and how do we measure the business impact when the answer is delivered inside the interface?”
Table of Contents
- Beyond Content Mills The New AI SEO Workflow
- Auditing Your Visibility in AI Search
- Prompting Content That Earns AI Citations
- On-Page Optimization Signals for AI Models
- Measuring ROI from AI Mentions and Citations
- AI SEO Governance and Common Pitfalls
- Frequently Asked Questions About AI SEO
Beyond Content Mills The New AI SEO Workflow
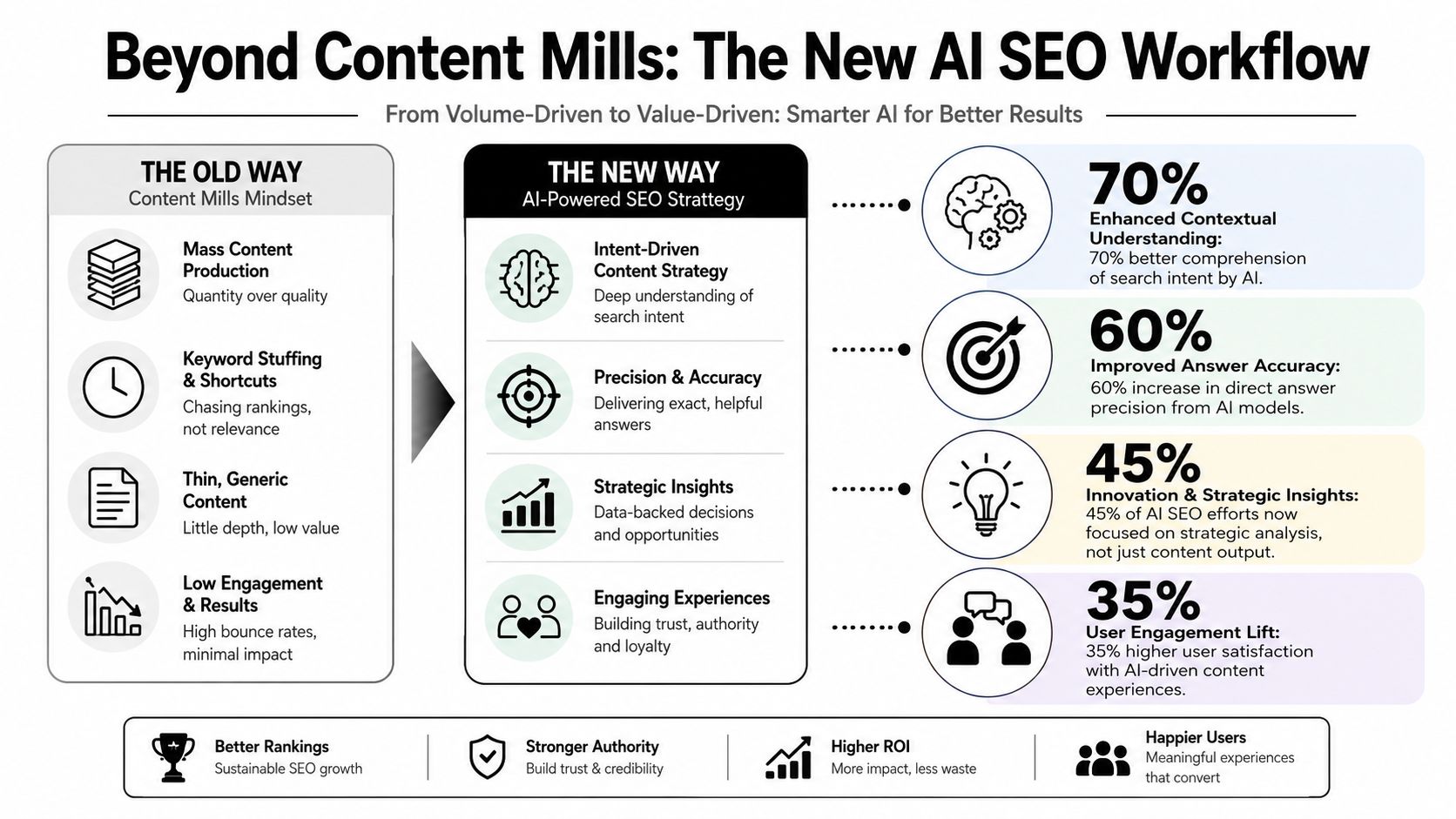
The content mill version of AI SEO is already stale. Teams that only use AI for drafting usually end up with a larger editorial backlog, a thinner review process, and very little improvement in actual market visibility.
The workflow that works looks different. It starts with prompt discovery, entity mapping, citation analysis, retrieval-friendly content structure, and measurement. Writing is only one step in that chain.
Semrush reported that almost 70% of businesses said they had seen higher ROI after integrating AI into SEO. The same Semrush analysis noted that Google AI Overviews reached 2 billion monthly users and roughly 60% of searches now yield no clicks. That combination is why old rank-and-click reporting is breaking down. If the user gets the answer in the interface, visibility still happened. Your standard dashboard may not show it clearly.
What the workflow actually changes
A modern AI SEO workflow shifts effort from bulk production to answer design:
- Research changes first: Teams mine query variants, related entities, and repeated user questions instead of building briefs around one exact-match keyword.
- Pages become retrieval assets: The page has to work at passage level, not just page level. That means headings with clear scope, concise answers near the top, and support details underneath.
- Success metrics change: Rankings still matter, but citation frequency, mention quality, prompt coverage, and branded presence inside AI responses matter more than they used to.
Practical rule: If your process can generate articles but can't tell you which prompts trigger your brand in AI answers, the workflow is incomplete.
This is why broad “publish more with AI” advice usually disappoints experienced teams. AI amplifies weak strategy just as fast as it amplifies strong strategy.
For eCommerce teams especially, the tactical overlap with product discovery is worth studying. NanoPIM's guide to generative AI for eCommerce is useful because it frames optimization around how AI surfaces products and brands, not just how pages rank.
What still doesn't work
A few patterns keep failing in practice:
- Generic top-of-funnel articles: They're easy to generate and hard to cite.
- Keyword insertion without answer depth: Models don't reward shallow coverage dressed up with semantically related terms.
- Reporting that stops at traffic: That misses exposure happening inside AI systems before the visit, branded search, or assisted conversion.
The new workflow is narrower, stricter, and more measurable. That's a good thing.
Auditing Your Visibility in AI Search
Before changing content, audit your current presence. Many practitioners skip this because traditional SEO habits push them straight into optimization. In AI search, that usually creates waste.
You need to know where your brand appears, which prompts trigger those appearances, how competitors show up in the same prompt sets, and whether the models cite you, summarize you, or ignore you.
Start with prompt sets, not keyword lists
Keyword tracking alone won't show how people phrase questions inside ChatGPT, Gemini, Perplexity, Copilot, or AI Overviews. Build prompt groups around real buying and research behavior.
A practical audit uses categories such as:
- Category prompts: “Best tools for…”, “top platforms for…”, “alternatives to…”
- Problem prompts: “How do I fix…”, “what causes…”, “why does…”
- Comparison prompts: “X vs Y”, “better than”, “which is best for”
- Brand prompts: Your company name, product names, executive names, and branded use cases
This work is more like demand mapping than classic rank tracking. The point is to see the conversation surface, not just the search result page.
Capture the answer, not just the mention
When your brand appears, log more than yes or no. Capture the response structure.
Use an audit sheet that records:
| Audit field | What to capture |
|---|---|
| Prompt | The exact user-style prompt entered |
| Model | ChatGPT, Gemini, Perplexity, Copilot, AI Overviews, or another system you monitor |
| Brand appearance | Mentioned, cited, summarized without citation, or absent |
| Position in answer | Lead recommendation, supporting mention, comparison entry, or footnote-style citation |
| Narrative | Positive, neutral, inaccurate, incomplete, or competitor-led framing |
| Source pattern | Which domains the model appears to rely on |
That narrative field matters. A brand can have visibility and still lose the interaction if the model frames the category around a competitor or surfaces outdated positioning.
An AI visibility audit should answer two questions fast: “Do we appear?” and “What story does the model tell when we do?”
Check where the model learned the answer
Many SEO teams often discover their first useful surprise: The page you expect to influence the answer often isn't the page doing the work. Sometimes a glossary page, help doc, product comparison, Reddit thread, or third-party review shapes the response more than the polished landing page.
If you need a practical framework for this diagnosis, this walkthrough on why your brand has zero AI search visibility and how to fix it is a solid reference for structuring the audit.
Benchmark the gaps that actually matter
Don't benchmark every prompt equally. Prioritize prompts that map to revenue motion.
For example:
- Buyer-intent prompts show whether you're present when users compare vendors.
- Category-definition prompts reveal whether you own the language around your market.
- Support and trust prompts show whether users encountering your brand get reassured or redirected.
One useful tool category here is AI visibility monitoring platforms. Spotlight Group LLC, for example, tracks brand mentions, prompts, and citation sources across major AI platforms. Teams also combine that type of monitoring with GA4, Search Console, manual prompt testing, and sales-call notes to connect presence with outcomes.
An audit gives you a baseline. Without that baseline, “search engine optimization using AI” turns into guesswork with better software.
Prompting Content That Earns AI Citations
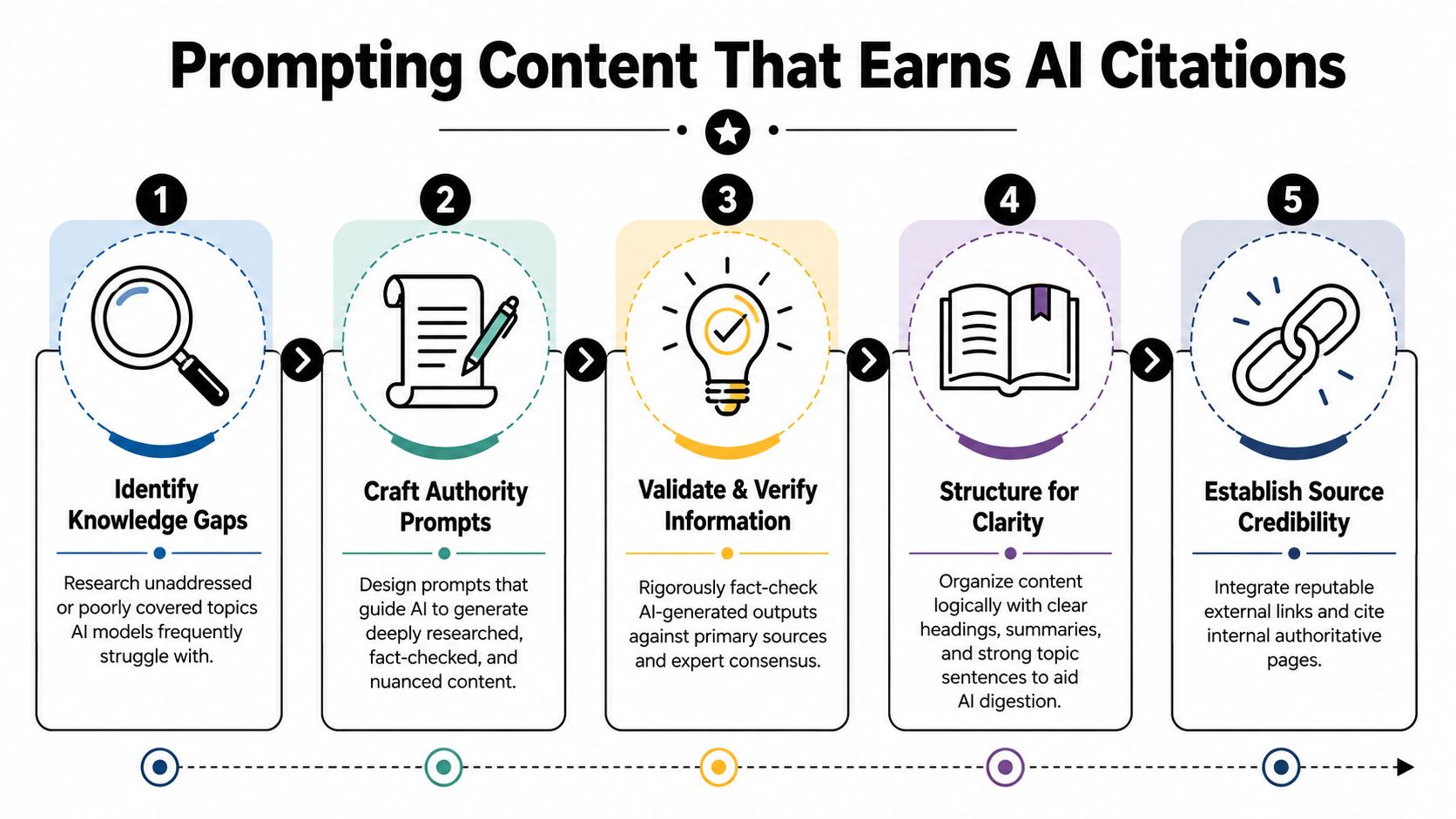
Citable content starts long before drafting. The prompt that creates the brief matters more than the prompt that writes the paragraph.
The job is to reverse-engineer the answer space. What questions appear repeatedly? What subtopics are missing from current pages? Which definitions, comparisons, and caveats make a model more likely to treat your page as usable source material?
BrightEdge notes that pages directly addressing specific user queries achieve 31% higher citation rates in AI-generated results. That changes how briefs should be built. Explicit question coverage is not a formatting preference. It's a performance lever.
Build briefs from question clusters
Single-keyword briefs underperform because they compress different intents into one target phrase. AI systems don't retrieve content that way. They assemble answers from passages that clearly address distinct questions.
A stronger briefing sequence looks like this:
Collect the query set
Pull search terms, customer questions, support tickets, sales-call objections, community threads, and prompt variants from AI platforms.Group by intent and entity
Separate definitions from comparisons, workflows from pricing questions, and beginner questions from evaluative ones.Draft a passage map
Decide which section answers which question. Don't let one section try to do too much.Add source demands
Mark every claim that needs verification, examples, or first-hand explanation before drafting starts.
Use prompts to create structure, not finished prose
Teams often over-prompt for style and under-prompt for coverage. That's backward.
A productive content brief prompt asks AI to produce:
- key questions users ask about the topic
- related entities and attributes that need mention
- a heading structure that answers those questions in logical order
- missing subtopics competitors often skip
- likely objections, caveats, or decision criteria
Then a human editor tightens the brief, adds product truth, removes generic filler, and sets factual guardrails.
Here's the standard I use: if the brief doesn't tell the writer what each section must answer, it isn't a brief. It's a topic suggestion.
Format for retrieval, not only readability
Good human UX and good retrieval formatting usually align, but not always. AI systems favor passages that are self-contained and easy to lift into an answer.
That means your page should include:
- Direct-answer openings: Answer the heading immediately, then expand.
- Scoped subheads: Write headings that signal a complete topic, not vague labels.
- Tight comparison sections: Present criteria cleanly so the model can reuse them.
- Visible definitions: Don't bury category basics under long intros.
- Selective Q&A blocks: Useful when the question is common and the answer can stand alone.
A detailed tactical resource here is Spotlight's guide on how to get ChatGPT to cite your content, especially if your team needs examples of citation-oriented structure.
Write every major section so it can survive extraction. If a paragraph loses meaning when pulled out of context, it's less likely to become a cited passage.
What usually breaks citation potential
The most common failures are operational, not creative.
| Weak pattern | Why it fails |
|---|---|
| Long intros before the answer | The model finds a clearer passage elsewhere |
| Broad headings like “Benefits” | Weak retrieval signal because scope is unclear |
| Repetitive SEO copy | Reads as optimized text, not source material |
| Unsupported claims | Increases editorial risk and weakens trust |
| FAQ spam | Too many low-value questions dilute the page |
The strongest pages don't sound “AI-written.” They sound like a knowledgeable operator answered the exact questions a buyer or researcher would ask, in the order they'd ask them.
On-Page Optimization Signals for AI Models
Traditional on-page SEO still matters. If a page is hard to crawl, poorly organized, or disconnected from the rest of the site, AI systems won't suddenly rescue it.
What changes is the unit of evaluation. AI systems often work with chunks, passages, and structured clues. A strong page gives them clean extraction points, clear meaning, and enough contextual depth to trust the answer.

Signals that improve machine interpretation
The pages that earn mentions consistently tend to share a few traits.
- Clear heading hierarchy: Each H2 and H3 should describe a distinct subtopic. Vague headers force the model to infer too much.
- Early answer placement: Put the answer near the top of the section, then expand with examples, edge cases, and trade-offs.
- Entity completeness: Name the core tools, concepts, audiences, alternatives, and attributes tied to the topic.
- Internal linking with purpose: Link related pages because they deepen topical context, not because a plugin suggested anchor text.
- Schema where it adds clarity: FAQ, HowTo, Product, Organization, and Article markup can help machines classify the page more cleanly.
A lot of teams hear “optimize for AI” and immediately chase exotic tactics. Most gains still come from disciplined page construction.
Passage-level optimization is the real shift
A ranking-era page could get by with one strong title, some backlinks, and acceptable topical coverage. AI-mediated discovery is less forgiving. The model may only use one paragraph from your article.
That changes editorial standards.
Consider the difference:
| Weak passage | Strong passage |
|---|---|
| Talks around the question | Answers it in the first sentence |
| Uses broad marketing language | Uses concrete, scoped language |
| Depends on earlier context | Makes sense as a standalone excerpt |
| Hides key detail in visuals | States the key detail in HTML text |
Make expertise legible
A page can be accurate and still look generic. That's often an authoring problem.
Use visible trust signals such as:
- named authors or editors where appropriate
- clear publication and update context
- cited sources when the topic requires verification
- examples from implementation, support, operations, or customer education
- language that acknowledges limits, exceptions, and trade-offs
Strong AI-visible pages don't just contain expertise. They display it in ways a machine can parse and a user can trust.
What to remove
Some page elements subtly hurt AI usability:
- Accordion-heavy pages that hide critical answers
- Image-only explanations without HTML equivalents
- Decorative intros that delay the useful part
- Template repetition that makes every section sound the same
- Thin comparison tables with labels but no interpretation
The target is clarity with substance. If a page is easy to parse but says little, it won't win. If it says a lot but is structurally messy, it won't get selected reliably either.
Measuring ROI from AI Mentions and Citations
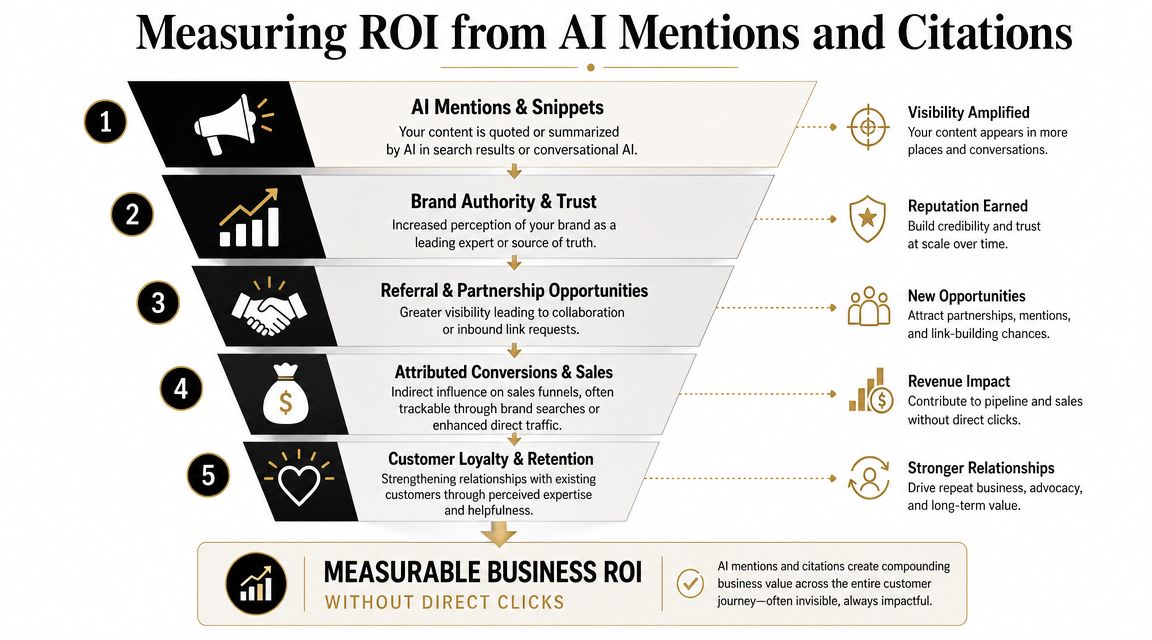
Most AI SEO advice frequently falters. It tells teams how to produce and optimize content, then stops before the finance question.
The hard part isn't getting an AI mention. The hard part is proving that mention created business value when the user may never click.
That measurement gap is real. As LLMrefs points out, a major underserved topic in AI SEO is how to measure ROI, because most guidance explains optimization tactics but not how to connect AI citations and brand mentions to business value when traditional click-based metrics are absent.
Start with an influence model, not a last-click model
If you treat AI visibility like paid search with missing referral data, you'll misread the channel.
A better approach is to model influence across four layers:
| Layer | What to observe |
|---|---|
| Presence | Does your brand appear for important prompts |
| Quality | Are you cited, recommended, or merely mentioned |
| Action | Do users search your brand, visit direct, or arrive through cited referral paths |
| Outcome | Do those sessions contribute to pipeline, qualified leads, or revenue |
This is closer to how PR, brand search, and analyst influence have always worked. AI search just makes the blind spot larger.
Use proxy metrics that connect to revenue motion
Not every useful metric is a final outcome metric. Some are leading indicators.
The most practical ones include:
- Citation frequency by prompt cluster: Shows whether your content is winning inclusion in commercially relevant topics.
- Branded prompt share: Reveals whether users ask for your brand by name inside AI interfaces.
- Referral patterns from citable engines: Some AI products pass source traffic more clearly than others.
- Lift in branded search behavior: Often one of the clearest signals that AI exposure is pushing users back into searchable demand.
- Sales-team hearing rate: If prospects increasingly mention having “seen” or “asked AI” before a demo, log it.
This broader framing aligns with the older SEO concept of share of voice, but the measurement object changes. If your team already uses search visibility models, adapting them to AI answer surfaces is a sensible next step. Spotlight's piece on share of voice SEO is useful here because it helps frame visibility as a market-level measure rather than a page-level vanity metric.
Tie prompts to journeys
The smartest reporting I've seen maps prompt classes to funnel stages.
For example:
- category education prompts map to early awareness
- alternatives and comparison prompts map to active evaluation
- implementation, pricing, and migration prompts map to purchase readiness
- support and trust prompts map to retention and expansion
That lets teams answer a more useful question than “did AI traffic convert?” They can ask, “where in the journey does AI visibility influence buyers, and which prompt clusters correlate with downstream conversion behavior?”
If you can't connect AI mentions to a buyer journey, you'll default back to rankings because they feel easier to explain.
Build a reporting cadence your leadership will trust
A workable monthly view includes:
- key prompt clusters monitored
- brand appearance and citation trends
- competitor comparison for those same prompts
- traffic patterns likely influenced by AI citation or brand recall
- assisted conversion notes from analytics and sales feedback
- content changes shipped and the visibility movement after those changes
That closes the loop from content production to business evidence. It also forces better prioritization. Teams stop publishing for volume and start publishing for measurable prompt coverage.
AI SEO Governance and Common Pitfalls
AI-assisted SEO without governance creates a clean-looking mess. The pages go live faster, but factual drift, inconsistent claims, and diluted brand voice pile up gradually until trust erodes.
A governance model should define who can use AI, where human review is mandatory, what sources are acceptable, how claims are verified, and which pages need legal, product, or subject-matter approval. This is not optional for enterprise teams, regulated categories, or any brand that depends on accuracy.
Common AI SEO Pitfalls and Mitigation Strategies
| Pitfall | Description | Mitigation Strategy |
|---|---|---|
| Over-automation | Teams publish AI drafts with light editing and assume speed equals output quality | Require editorial review before publication and assign clear approval owners |
| Generic briefs | Writers get a topic, a keyword, and a word count, but no intent map or question set | Build briefs around prompt clusters, entities, and required answers |
| Unverified claims | AI inserts statements that sound credible but lack proof | Mark every factual claim for source review before publishing |
| Brand voice drift | Different teams use different prompts and outputs start sounding inconsistent | Create reusable prompting standards, tone rules, and example libraries |
| Hidden accountability | Nobody owns post-publication QA, updates, or response monitoring | Assign owners for content quality, model visibility tracking, and refresh cycles |
The biggest mistake is treating AI as an author instead of an assistant inside a controlled workflow. Teams that govern inputs, reviews, and measurement usually improve faster than teams that publish more.
Frequently Asked Questions About AI SEO
Common questions and direct answers
| Question | Answer |
|---|---|
| Is AI SEO the same as using ChatGPT to write blog posts? | No. Writing is one use case. AI SEO includes prompt research, content clustering, on-page structuring, citation tracking, and ROI measurement. |
| Does traditional SEO still matter? | Yes. Crawlability, internal linking, topical authority, and strong page structure still support discovery and selection. AI search adds another layer. It doesn't replace the basics. |
| Should every page have an FAQ section? | No. Add FAQs when they answer real follow-up questions. Forced FAQs often dilute the page and make it feel templated. |
| What type of content gets cited most often? | Content that answers specific questions clearly, uses strong heading structure, and covers related context without fluff tends to be more citable. |
| Can you measure value if AI mentions your brand without a click? | Yes, but not with last-click thinking alone. Track prompt coverage, citation trends, branded search behavior, direct traffic patterns, and assisted conversion signals together. |
| Which teams should own AI visibility? | Usually SEO leads the work, but content, analytics, PR, product marketing, and compliance often need shared ownership. |
| Will generative AI replace search engines? | It's more useful to think in layers. AI interfaces increasingly mediate discovery, but search infrastructure still matters underneath. This overview of Generative AI vs. search engines is a helpful framing reference. |
A realistic expectation helps. Search engine optimization using AI won't reward teams for scaling mediocre content faster. It rewards teams that can identify the prompts that matter, create pages that answer them better than competitors, and prove that AI visibility influenced revenue even when the click never happened.
The teams that win this shift won't separate content from measurement. They'll treat them as one operating system.
If you need that operating system in practice, Spotlight Group LLC helps brands monitor AI mentions, prompts, and citations across major AI platforms, then connect that visibility back to business impact.
Drafted with the Outrank tool